常见的分布式并行策略 数据并行、模型并行、混合并行 By SeaMount, Words: 9137 Posted on November 21, 2023 近年来,随着模型规模的不断扩大,训练一个单独的模型所需要的算力和内存要求也越来越高。然而,由于内存墙的存在,单一设备的算力以及容量受到限制,而芯片的发展却难以跟上模型扩大的速度。为了解决算力增速不足的问题,人们开始考虑使用多节点集群进行分布式训练,以提升算力。 [Read More] Tags: MLSys Parallelism
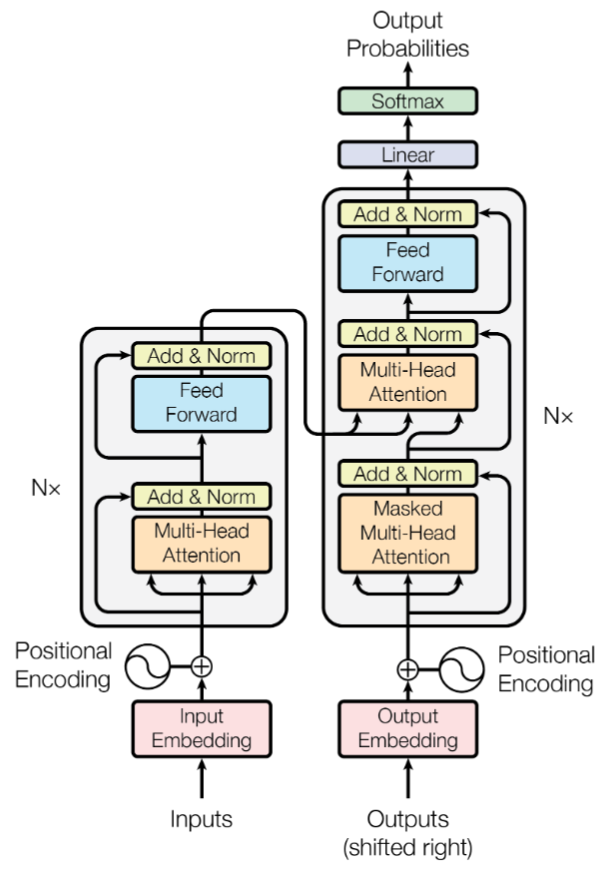
Transformer 模型结构不完全详解 Transformer 究竟是什么? By SeaMount, Words: 7137 Posted on November 18, 2023 2017 年 Google Brain 在 NeurIPS 上面发表了论文 Attention Is All You Need,文章中提出了一种新的 seq2seq 模型 —— Transformer。Transformer 舍弃了先前的 RNN/CNN 结构,采用 encoder-decoder 的结构,只使用注意力模型来进行序列建模,解决了之前 RNN 固有顺序不能并行化的缺点,Transformer 对于长序列语义的捕获能力也比先前的 RNN 结构更强。 [Read More] Tags: llm Transformer
自动微分 By SeaMount, Words: 6445 Posted on November 13, 2023 自动微分在很多领域都被广泛使用,但直到深度学习出现时,才被用于计算机领域对程序做高效准确的求导。随着自动微分和其它微分技术的深入研究,其与编程语言、计算框架、编译器等领域的联系愈发紧密,并且衍生扩展出更通用的可微编程概念。 [Read More] Tags: Auto Diffrentiate
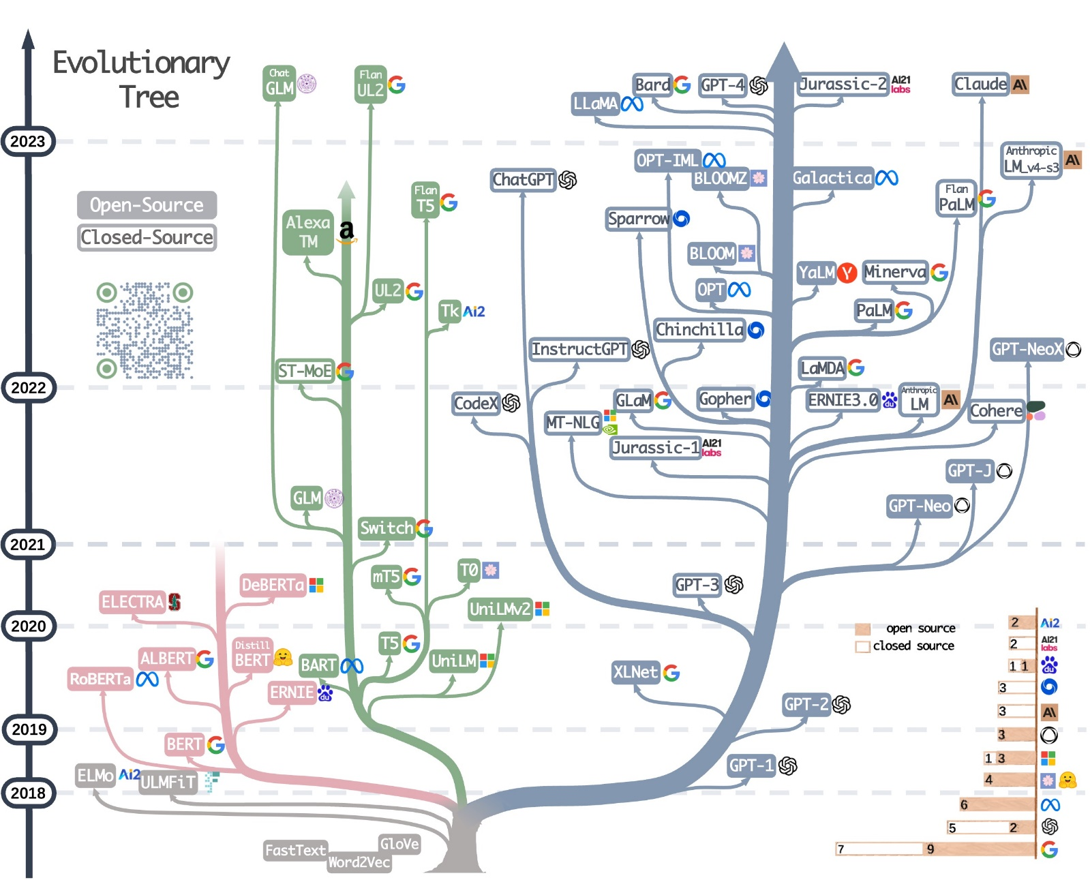
Google & OpenAI 大模型之战 By SeaMount, Words: 4178 Posted on November 1, 2023 图源: Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond [Read More] Tags: llm Google OpenAI
OAuth认证流程、Access Token 以及 Refresh Token简介 By SeaMount, Words: 2333 Posted on October 18, 2020 很多的网站、APP 都弱化了甚至没有搭建属于自己的账号体系,而是使用其它社会化的第三方登陆的方式,比如在登陆某个网站的时候选择通过 github 或者微信、微博等方式登陆,这样不仅免去了用户注册账号的麻烦,还可以获取用户的好友关系来增强自身的社交功能。 [Read More] Tags: OAuth