图形处理器(Graphics Processing Unit, GPU),又称显卡核心、视觉处理器或显卡芯片,是一种专门在 PC、工作站、游戏机和一些移动终端上进行图像计算工作的处理器。20 世纪 80 年代之前,计算机的图形计算和处理工作都是由 CPU 完成的,而近几十年里,图形处理技术的重大变革,特别是图形界面操作系统(如微软的 Windows、国产的麒麟等)的出现和普及推动了新型图形处理器架构的更迭,GPU 也不再是只能作为辅助 CPU 的简单图像处理设备,逐渐发展为如今的通用高性能并行计算工具。
Nvidia 于 1999 年 8 月 发明了全球第一个 GPU——GeForce 256。当今的 GPU 在算术吞吐量和内存带宽方面远远超过了 CPU,使其成为加速各种数据并行应用程序的理想处理器。
本文梳理了自 Fermi 架构到 Hopper 架构以来,Nvidia 各个 GPU 架构的演变。
Fermi
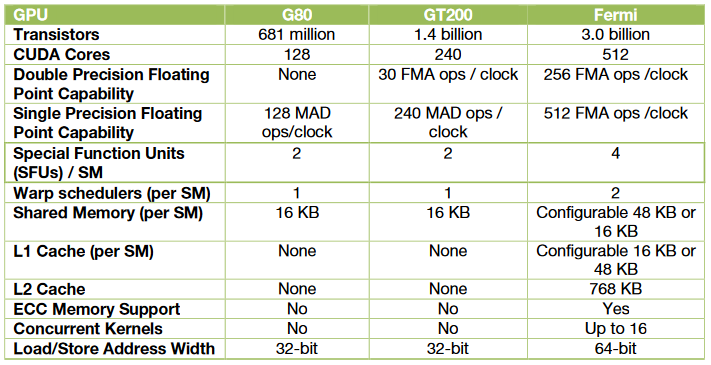
Fermi 架构是自最初的 G80 以来 GPU 架构中最重大的飞跃。G80 是对统一图形和计算并行处理器的最初设想。 GT200 扩展了 G80 的性能和功能。Fermi 汲取了 G80 和 GT200 架构的经验以及为其编写的所有应用程序中学到的所有知识,并采用全新的设计方法来创建世界上第一个计算 GPU。在 Fermi 架构出现之前,使用 GPGPU 的程序员有以下诉求:
- 提高双精度性能:虽然单精度浮点性能大约是 CPU 性能的十倍,但一些 GPU 计算应用程序也需要更高的双精度性能。
- ECC(Error correction) 纠错码支持:ECC 允许 GPU 计算用户在数据中心安装中安全地部署大量 GPU,并确保医疗成像和金融期权定价等数据敏感应用程序免受内存错误的影响。
- 真实的缓存架构:一些并行算法无法使用 GPU 的共享内存,用户需要一个真正的缓存架构来帮助他们。
- 更多的共享内存:许多 CUDA 程序员需要超过 16 KB 的 SM 共享内存来加速他们的应用程序。
- 更快的上下文切换:应用程序之间更快的上下文切换以及更快的图形和计算互操作。
- 更快的原子操作:为并行算法提供更快的读取-修改-写入原子操作。
Fermi 架构针对上述诉求改进了 GPU,取得了以下的突破:
- 第三代流式多处理器(SM)
- 32 CUDA cores / SM,4x over GT200
- 8x 于 GT200 的峰值双精度浮点性能
- 双 warp 调度器,同时调度(schedule)和分派(dispatch)来自两个独立 warp 的指令
- 64 KB 的 RAM,具有可配置的共享内存分区和 L1 缓存
- 第二代并行线程执行 ISA
- 具有完整 C++ 支持的统一地址空间
- 针对 OpenCL 和 DirectCompute 进行了优化
- IEEE 754-2008 32 位和 64 位精度
- 具有 64 位扩展的完整 32 位整数路径
- 支持过渡到 64 位寻址的内存访问指令
- 通过预测提高性能
- 改进了内存子系统
- 具有可配置的 L1 和 L2 缓存的英伟达并行数据缓存层次结构
- 第一个支持 ECC 的GPU
- 大幅提升原子内存操作性能
- Nvidia GigaThread 引擎
- 上下文切换速度加快 10 倍
- 并发内核执行
- 无序的线程块执行
- 双向重叠内存传输引擎
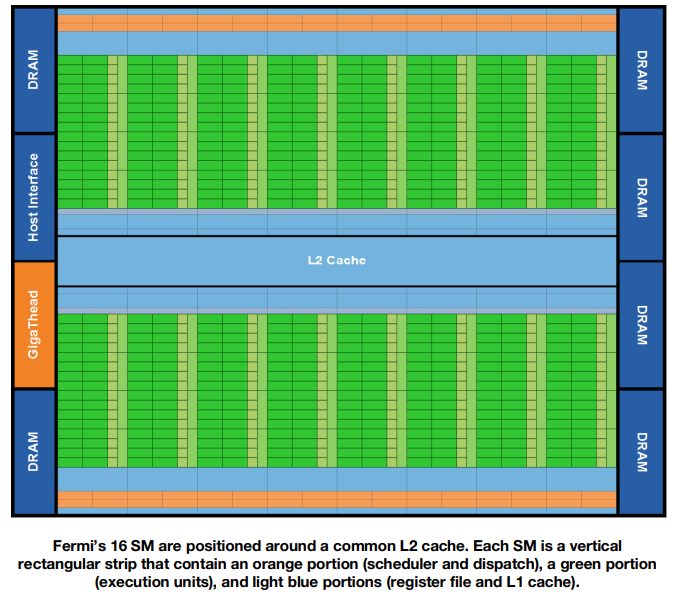
第一个基于 Fermi 的 GPU 采用 3B 个晶体管实现,最大可支持 16 个 SMs,Fermi 架构中一共有 512 个 CUDA Cores,一个 CUDA Core 可以为一个线程的每个时钟周期执行一条浮点或整数指令。整个 GPU 有多个 GPC(图形处理器),单个 GPC 包含一个光栅引擎(Raster Engine),4 个 SM。整个 GPU 具有 6 个 64 位内存分区,适用于 6 \(\times\) 64 = 384 位内存接口,总共支持高达 6 GB 的 GDDR5 DRAM 内存。主机接口通过 PCI-E 将 GPU 连接到 CPU。 GigaThread 全局调度程序将线程块分配给 SM 线程调度程序。
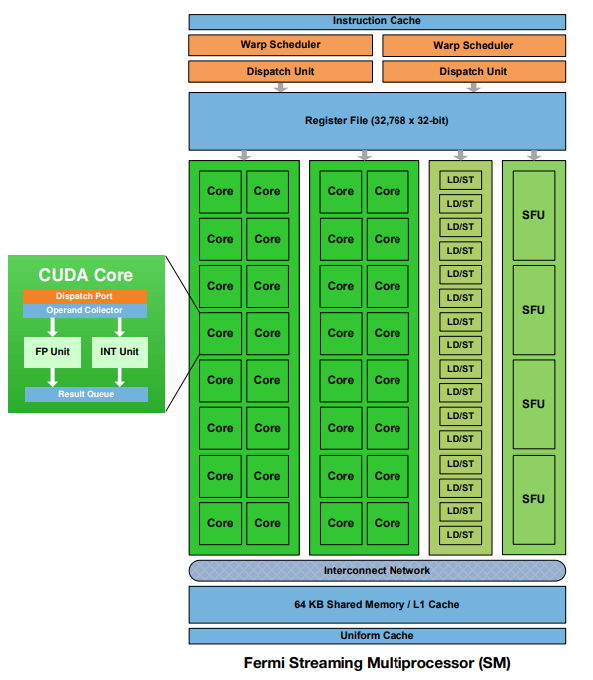
每个 SM 有 32 个 CUDA Cores,即以 32 个线程为一组执行线程,称为 warp。每个 CUDA Core 都有一个 32-bit 整数算术逻辑单元(ALU)和浮点运算单元(FPU)。Fermi 架构实施新的 IEEE 754-2008 浮点标准,为单精度和双精度算术提供乘加(FMA)指令。FMA 通过使用单个最终舍入步骤执行乘法和加法,改进了乘加(MAD)指令,并且不会损失加法的精度。每个 SM 有 16 个 LOAD/STORE 单元,允许每个时钟计算 16 个线程的源地址和目标地址。支持单元将每个地址处的数据加载并存储到高速缓存或 DRAM 中。每个 SM 具有 64KB 的片上内存,可以配置为 48KB 共享内存和 16KB L1 Cache,或者配置为 16KB 的共享内存和 48KB 的 L1 Cache。
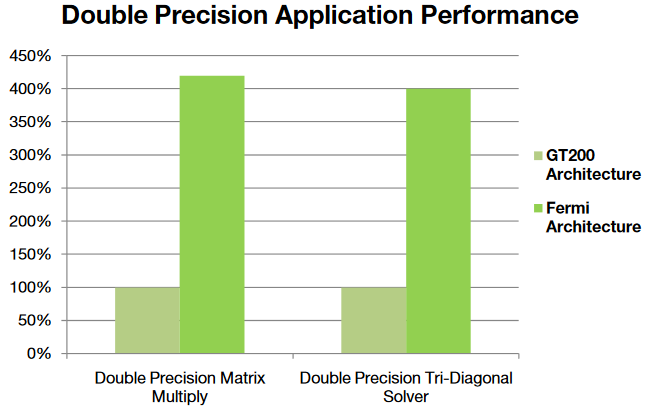
每个 SM,每个时钟可以执行多达 16 个 双精度 FMA 操作。
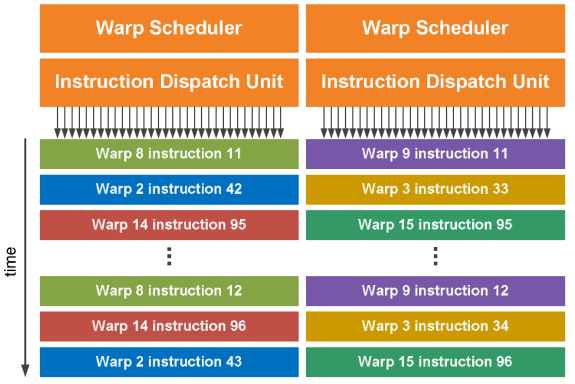
SM 以 32 个并行的线程为一组(称为 warps)来调度线程。每个 SM 具有两个 warp 调度器(scheduler)和两个指令调度单元(Instruction dispatch unit),允许两个 warp 同时发出和执行。 Fermi 的双 warp 调度器选择两个 warp,并从每个 warp 向一组 16 个 cores、16 个 LD/ST 单元或 4 个 SFU 发出一条指令。由于 warp 独立执行,Fermi 的调度程序不需要检查指令流内的依赖关系。可以同时发出两条整数指令、两条浮点指令或整数、浮点、加载、存储和 SFU 混合的指令。双精度指令不支持与任何其他操作的双重调度。
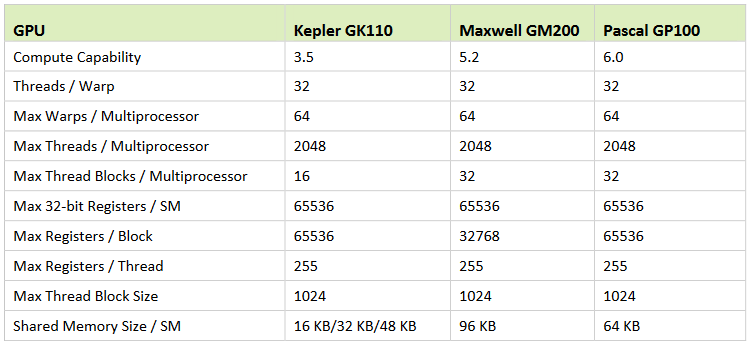
Kepler
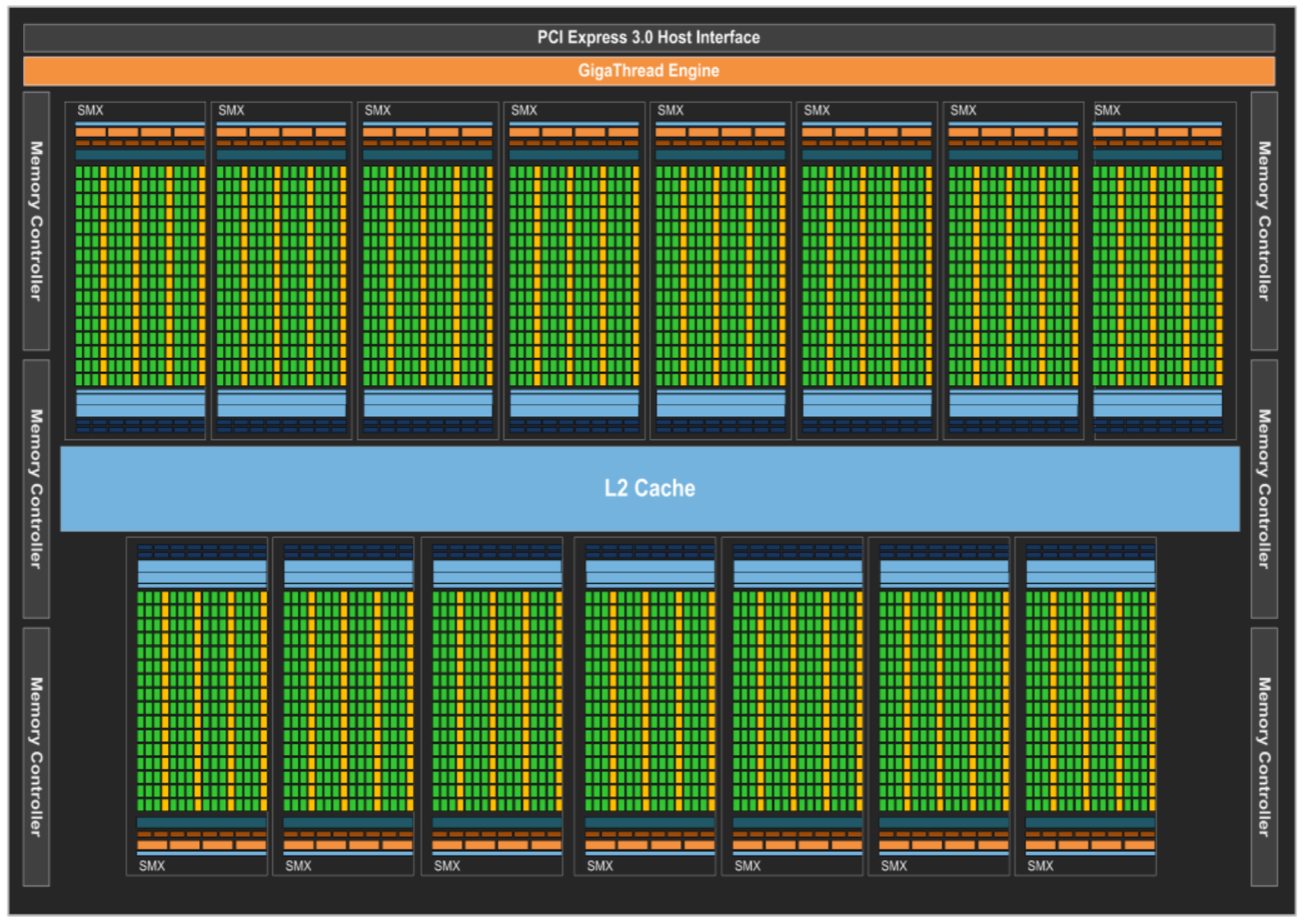
随着科学、医学、工程和金融等许多领域对高性能并行计算的需求不断增加,NVIDIA 不断创新,并通过极其强大的 GPU 计算架构来满足这一需求。 NVIDIA 的 GPU 已经重新定义并加速了地震处理、生物化学模拟、天气和气候建模、信号处理、计算金融、计算机辅助工程、计算流体动力学和数据分析等领域的高性能计算 (HPC) 功能。 Kepler GK110/210 架构由 7.1B 个晶体管组成,集成了许多专注于计算性能的创新功能。
Kepler 架构使用了以下功能提高了 GPU 的利用率,简化了并行程序设计:
- 动态并行:使得应用程序的大部分代码能完全在 GPU 上运行;
- Hyper-Q:使多个 CPU 核能够同时在单个 GPU 上启动,从而显著提高 GPU 利用率并显著减少 CPU 空闲时间,允许来自多个 CUDA 流、多个消息传递接口(MPI)进程,甚至进程内的多个线程的单独连接;
- 网格管理单元:GMU 可以暂停调度新网格,并将暂停的网格进行排队,直到它们准备好执行为止;
- GPUDirect 技术:可以绕过 CPU/System Memory,完成其与本机其它 GPU 或者其它机器 GPU 的直接数据交换;
Kepler 架构将 SM 改名为了 SMX,但是所代表的概念没有大变化,其在硬件上直接有双精度运算单元。一个完整的 Kepler 架构包括 15 个 SMX 单元内核 6 个 64 位内存控制器。提供了额外的缓存功能、层次结构
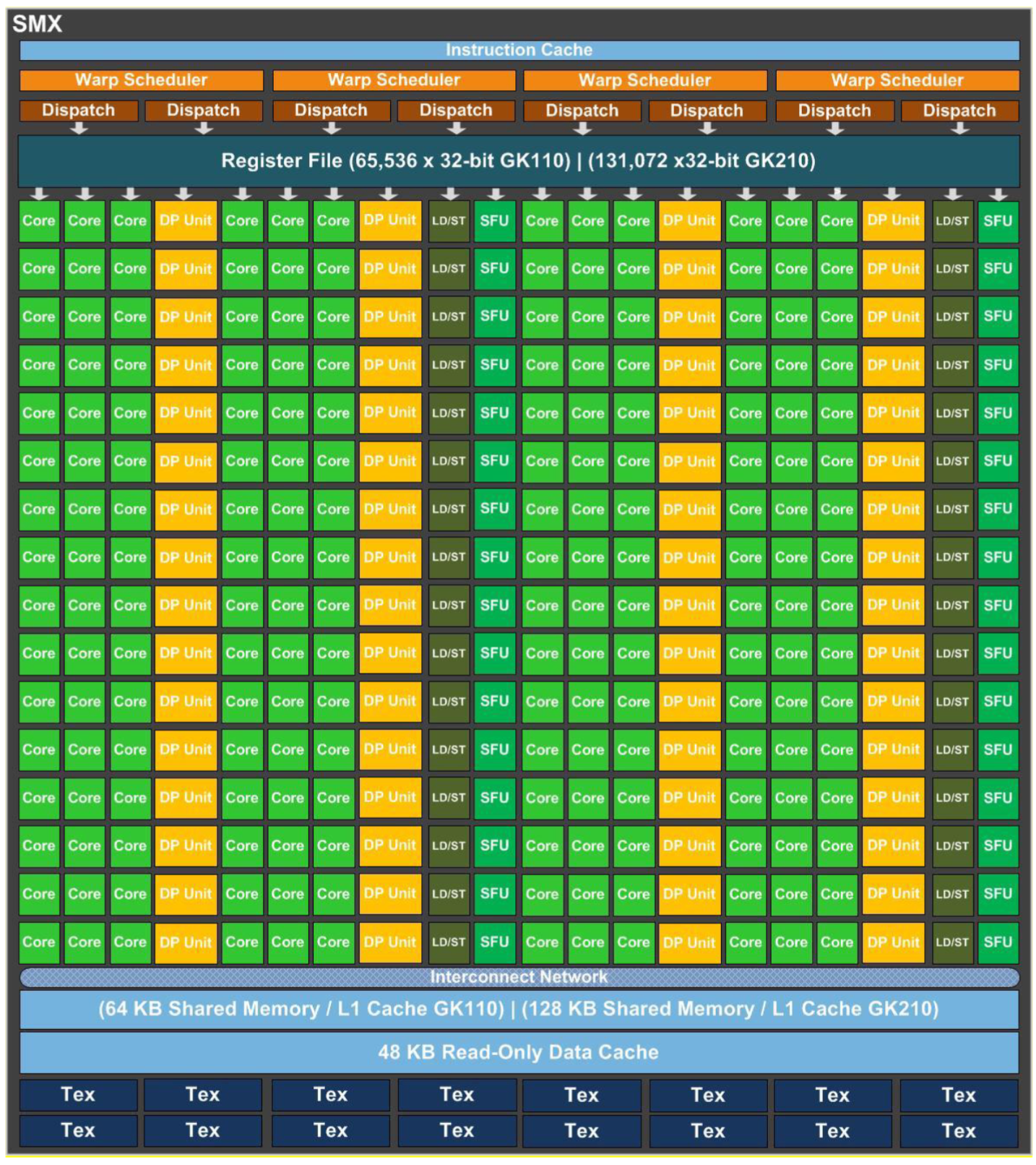
一个 SMX 有 192 个单精度 CUDA Cores,64 个双精度单元,32 个特殊功能单元(SFU)和 32 个 LD/ST。每个 CUDA Core 具有浮点运算单元和整数算数逻辑单元。Kepler 保留了 Fermi 中引入的 IEEE-754-2008 标准的单精度和双精度算数,包括 FMA 运算。SMX 以 32 个并行线程位一组(称为 warps)来调度线程。每个 SMX 具有 4 个 warp 调度器和 8 个指令调度单元,允许同时发出和执行 4 个 warp。与 Fermi 架构不允许双精度指令与其它指令配对不同的是,Kepler 允许双精度指令与其它指令配对。
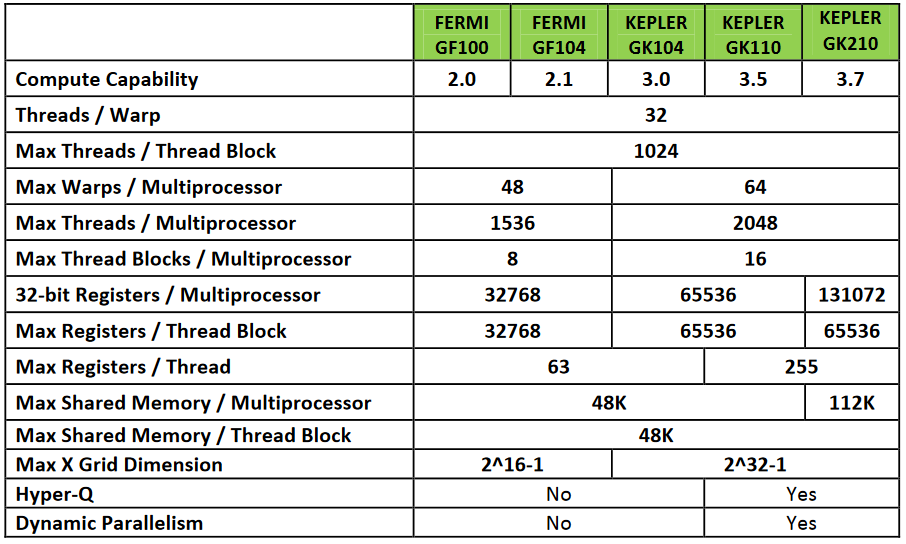
Kepler 架构的计算能力和 Fermi 架构计算能力对比:
为了进一步提高性能,Kepler 实现了 Shuffle 指令,允许 warp 内的线程共享数据。以前,在 warp 内的线程之间共享数据需要单独的 LD/ST 操作才能通过共享内存传递数据。与共享内存相比,Shuffle 具有性能优势,因为 LD/ST 操作是在一个步骤中执行的。Shuffle 还可以减少每个线程块所需的共享内存量,因为在 warp 级别交换的数据永远不需要放置在共享内存中。
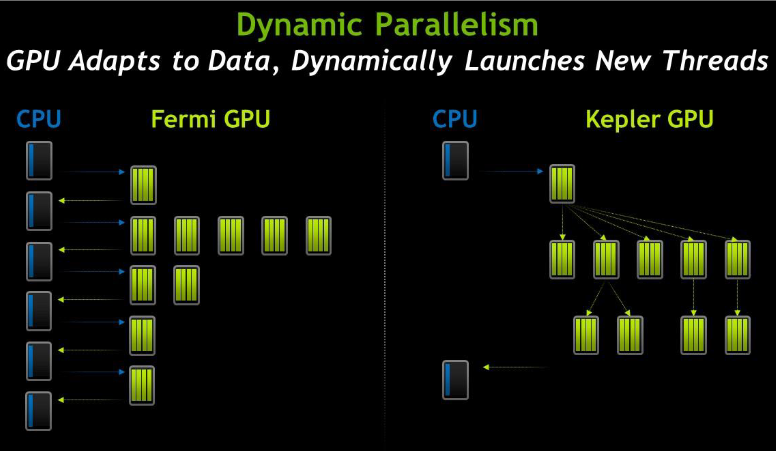
Fermi 架构中,所有任务均从 CPU 启动,运行完成,将结果返回给 CPU。在 Kepler 中,任何内核都可以启动另一个内核,可以创建必要的流、事件并管理处理其他工作所需的依赖项,无需主机 CPU 交互。这种架构创新使开发人员能够更轻松地创建和优化递归和数据相关的执行模式,并允许更多程序直接在 GPU 上运行。动态并行允许更多代码由 GPU 直接启动,而不需要 CPU 干预。
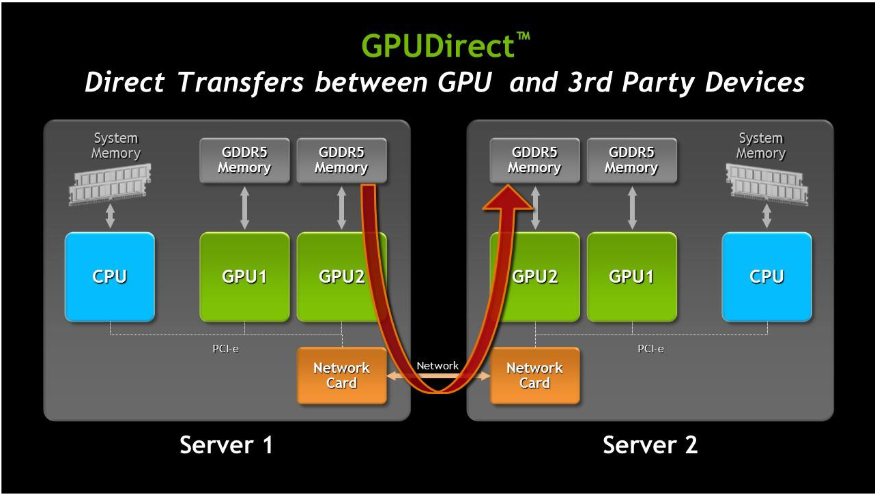
处理大量数据时,增加数据吞吐量和减少延迟对于提高计算性能至关重要。 Kepler 支持 NVIDIA GPUDirect 中的 RDMA 功能,它允许 IB 适配器、NIC 和 SSD 等第三方设备直接访问 GPU 内存,显著降低 MPI 向 GPU 内存发送消息和从 GPU 内存接收消息的延迟,提高了性能,与此同时,还减少了对系统内存带宽的需求,并释放 GPU DMA 以供其它 CUDA 任务使用。使用 CUDA 5.0 或更高版本时,GPUDirect 提供以下重要功能:
- NIC 和 GPU 之间 DMA,无需 CPU 端数据缓冲;
- 显着提高了 GPU 与网络中其他节点之间的 MPISend/MPIRecv 效率;
- 消除 CPU 带宽和延迟瓶颈;
- 适用于各种第三方网络、捕获和存储设备;
Maxwell
Maxwell GPU 的设计初衷是为了实现极高的能效和功耗比。
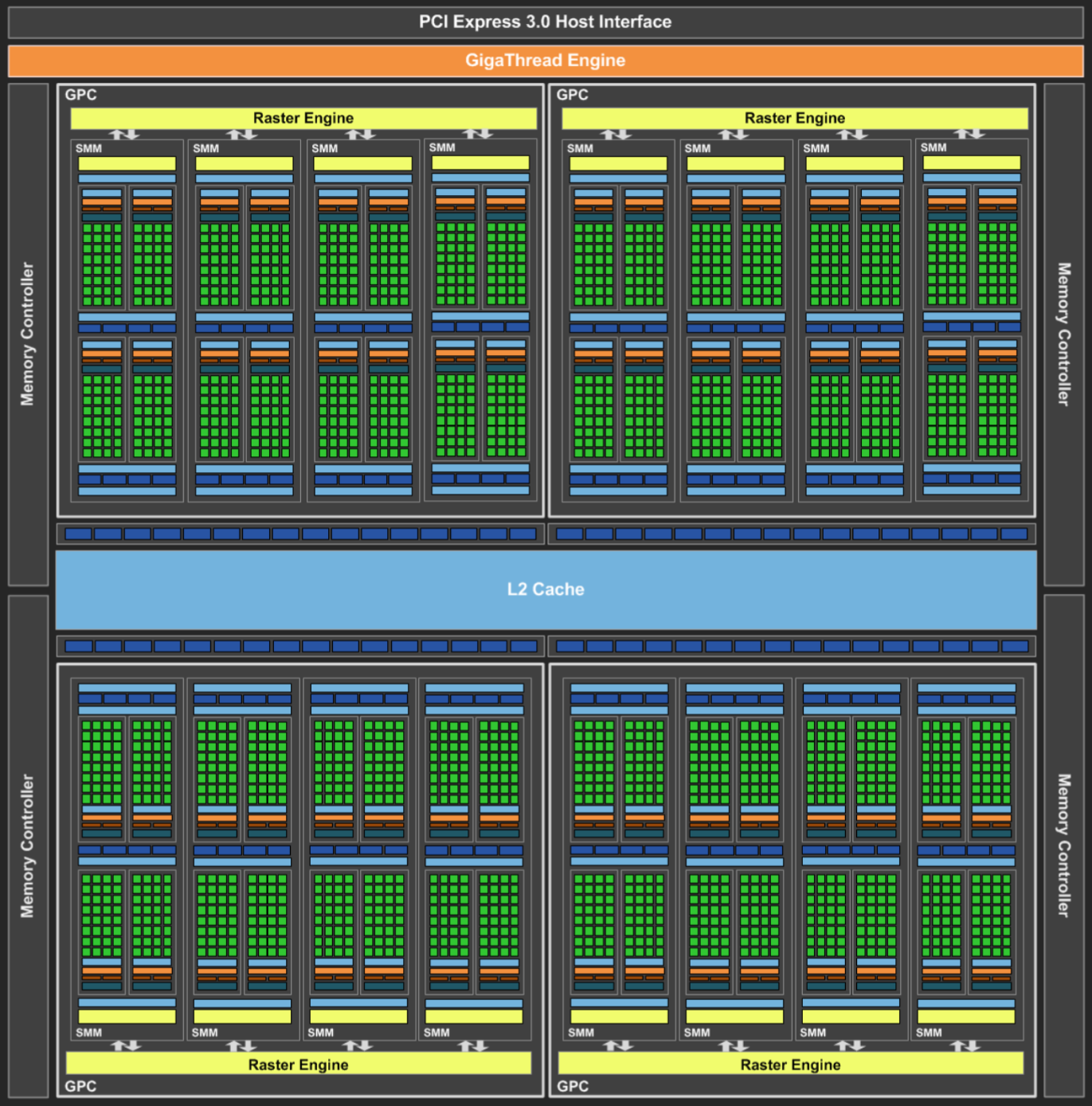
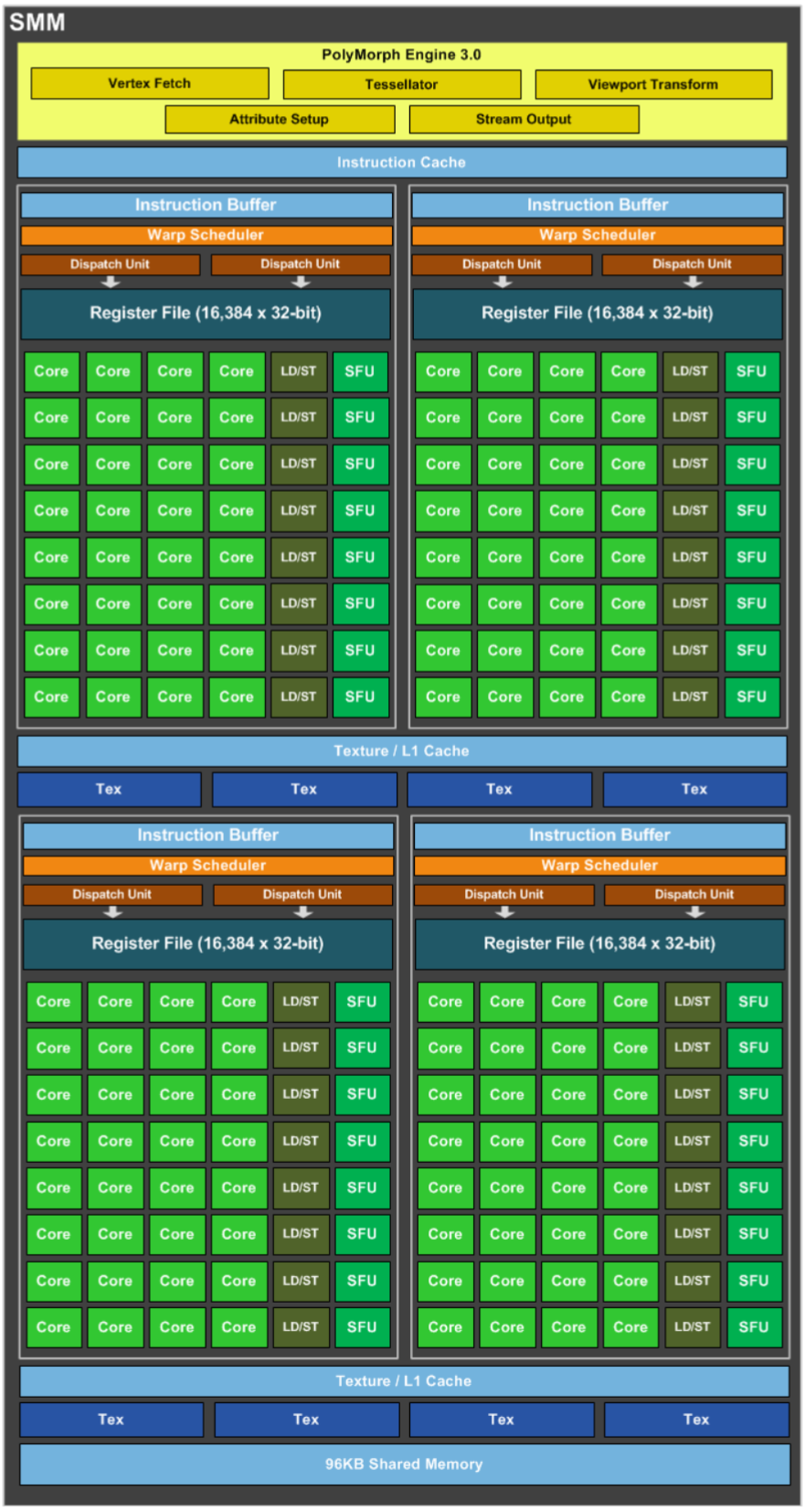
Maxwell 采用了完全改进的芯片拓扑,SM 分为四个独立的 CUDA 核心处理块,每个块都有自己的专用资源用于调度和指令分派。一个 SMX 有 128 个 CUDA Core,核心数减少了,但是线程数可以超配。
Pascal
使用了 Pascal 架构的 P100 的主要特性有:
- NVLink
- HBM2
- 统一内存,计算抢占和新的 AI 算法
- 16nm FinFET
Tesla P100 是第一个支持 HBM2 的 GPU 架构,HBM2 是堆叠内存,与 GPU 位于同一物理封装上,相较于传统的 GDDR5,可以节省大量空间。HBM2 提供的内存带宽是 Maxwell GM200 GPU 的 3 倍。P100 能够以更高的带宽处理更大的工作数据集,从而提高效率和计算吞吐量,并降低系统内存传输的效率。
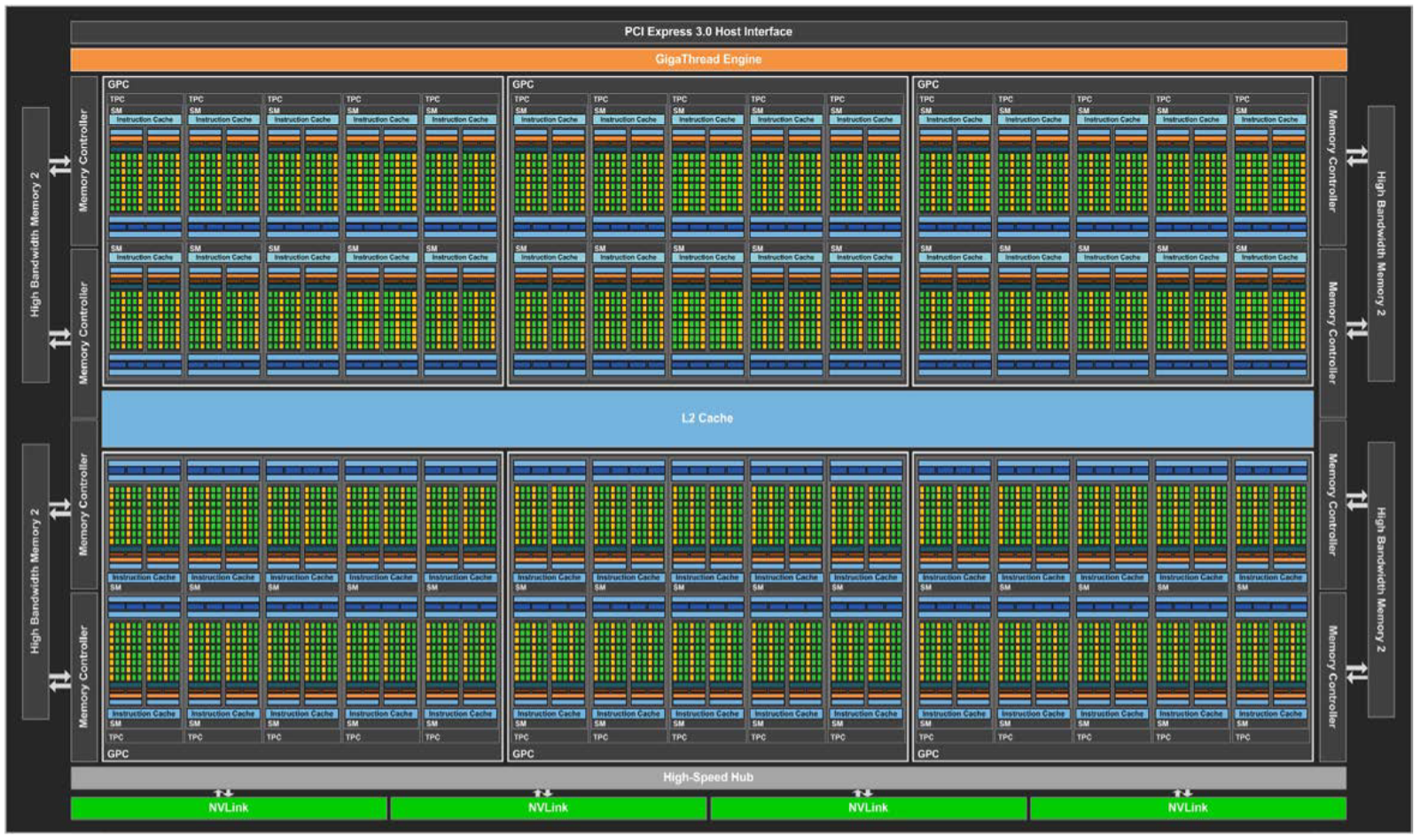
完整的 GP100 由 6 个 GPC、60 个 Pascal SM(供 3840 个单精度 CUDA Cores 和 240 个 Texture Units)、30 个 TPC(每个包含 2 个 SM)和 8 个 512 位内存控制器(总共 4096 位)组成。GP100 内的每个 GPC 有 10 个 SM。每个 SM 有 64 个 CUDA 核心和 4 个 Texture Units。每个内存控制器都连接到 512 KB 的 L2 缓存,每个 HBM2 DRAM 堆栈由一对内存控制器控制。完整的 GPU 包含总共 4096 KB 的二级缓存。Tesla P100 使用了 56 个 SM。
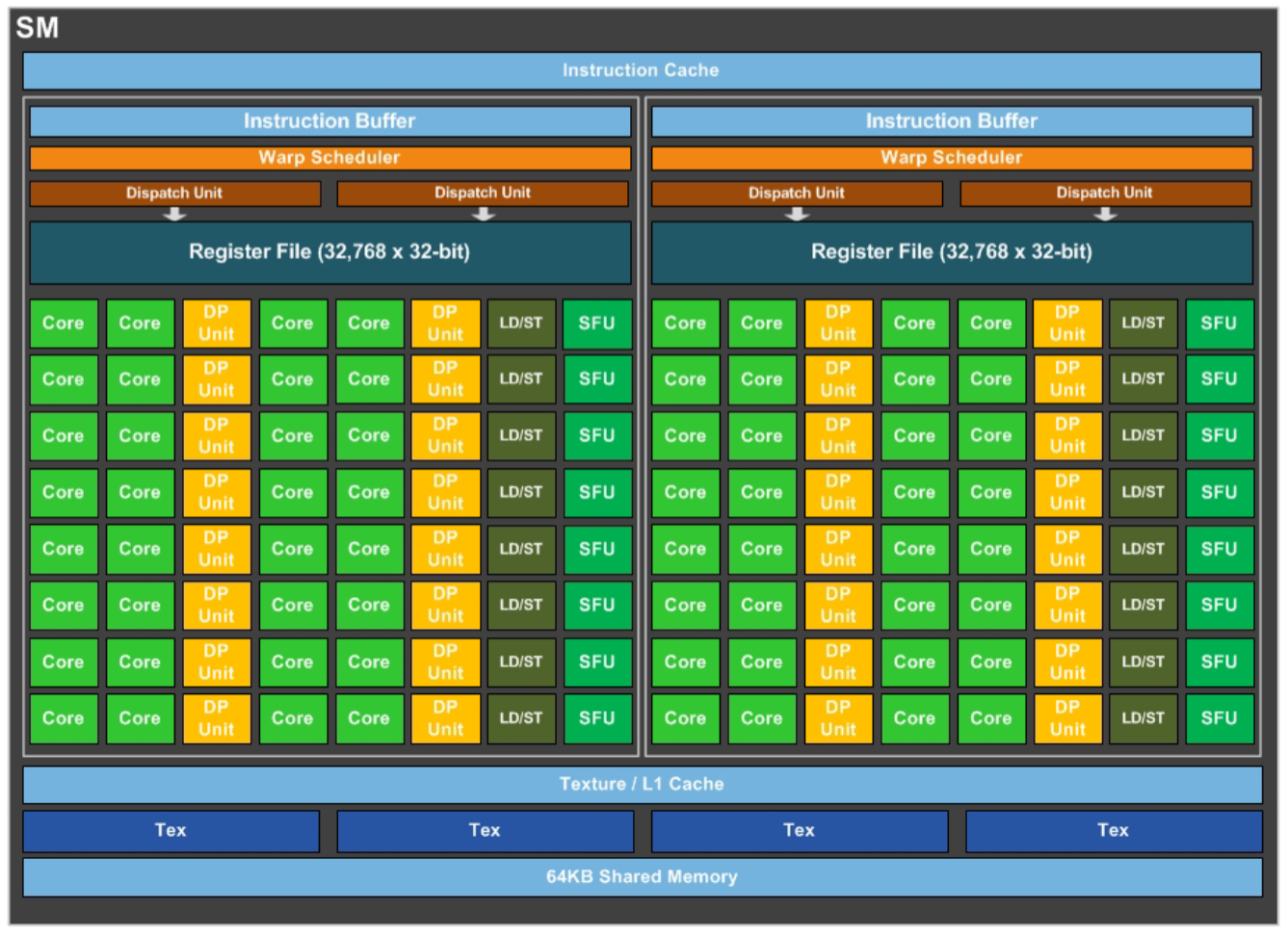
SM 内部做了进一步的精简,整体精简思路是 SM 内部包含的东西越来越少,但是总体片上的 SM 数量每一代都在不断增加。
单个 SM 只有 64 个 FP32 CUDA Cores,相比 Maxwell 的 128 和 CUDA Cores 和 Kepler 的 192 个 CUDA Cores,这个数量要少很多,并且 64 个 CUDA Cores 分为了两个区块。FP32 CUDA Core 具备处理 FP16 的能力,FP16 的吞吐量高达 FP32 吞吐量的 2 倍,且在 GP100 中,可以使用单个成对的操作指令执行两个 FP16 操作。Registre File 保持相同大小,每个线程可以使用更多寄存器,单个 SM 也可以并发执行更多的 thread/warp/block。每个 SM 还增加了 32 个 FP64 CUDA Cores(DP Unit)。
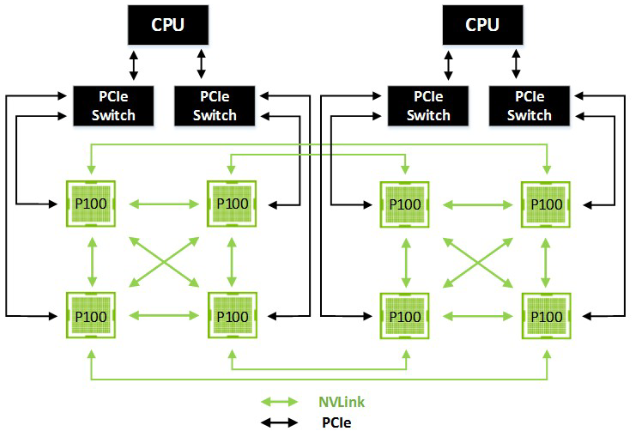
多机之间,采用 InfiniBand 和 100Gb 以太互联,形成更强大的系统,单机内单 GPU 到单机 8 GPU,PCI-E 带宽称为拼接。NVLink 用以单机内多 GPU 内的点到点通信,可提供 160GB/s 的双向带宽的 GPU-GPU 通信,大约 5x 于 PCI-E 3 \(\times\) 16。
Volta
- CUDA Core 拆分:分离了 FPU 和 ALU,取消 CUDA Core,一条指令可以同时执行不同计算;
- 独立线程调度:改进 SIMT 模型架构,使得每个线程都有独立的 PC(Program Counter)和 Stack;
- Tensor Core:针对深度学习提供张量计算核心,专门针对卷积计算进行加速;
- GRF & Cache:Global memory 访问也能享受 highly banked cache 加速;
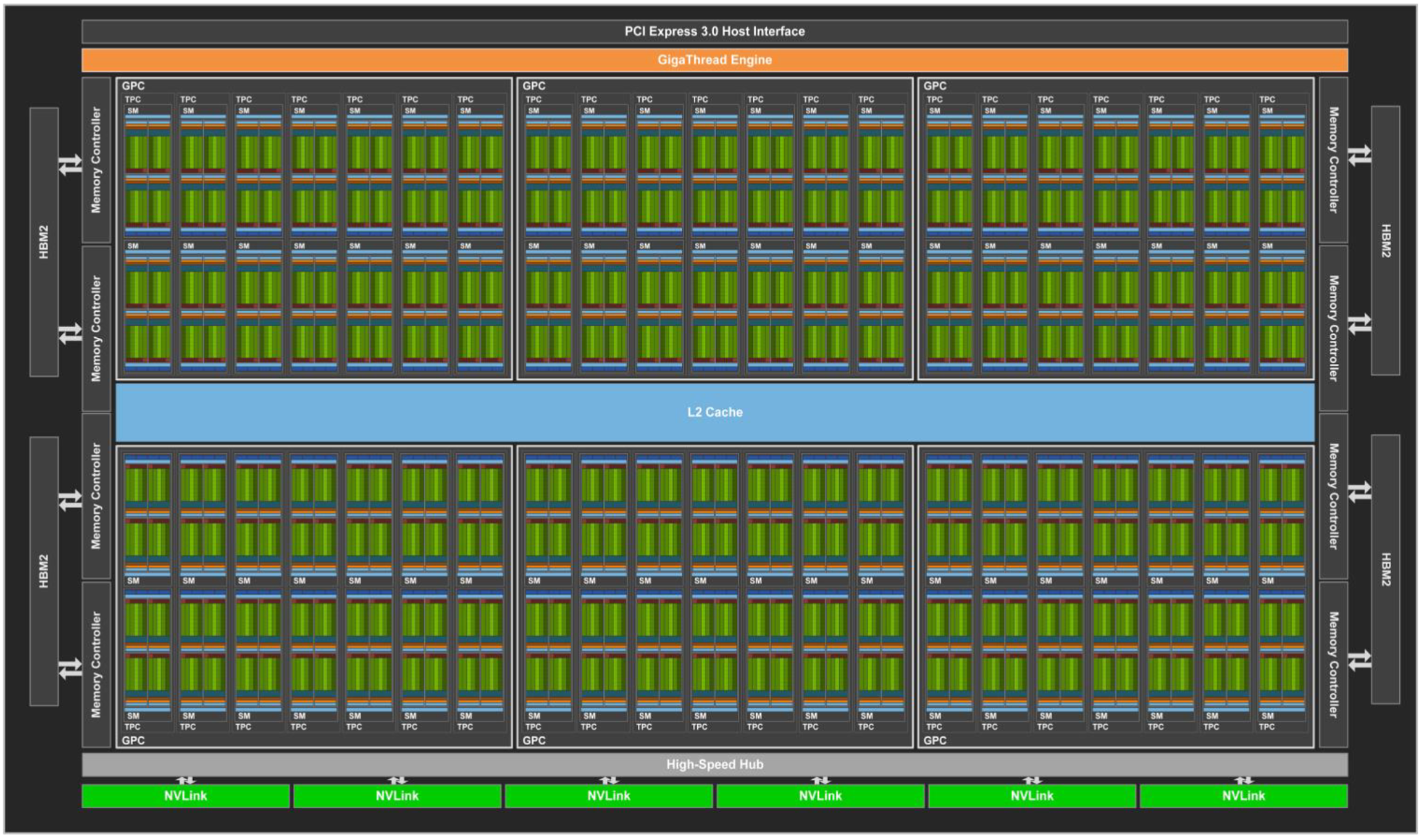
完整的 GV100 GPU 包括:
- 6 个 GPC,每个 GPC 包含:
- 7 个 TPC(每个 TPC 有 2 个 SM)
- 14 个 SM
- 84 个 Volta SM,每个 SM 包含:
- 64 个 FP32 Cores
- 64 个 INT32 Cores
- 32 个 FP64 Cores
- 8 个 Tensor Cores
- 4 个 Texture Units
- 8 个 512 位内存控制器(总共 4096 位)
完整的 GV100 GPU 共有 5376 个 FP32 Cores、5376 个 INT32 Cores、2688 个 FP64 Cores、672 个 Tensor Cores 和 336 个 Texture Units。每个 HBM2 DRAM 堆栈均由一对内存控制器控制。完整的 GV100 GPU 包含总共 6144 KB 的二级缓存。Tesla V100 加速器使用 80 个 SM。
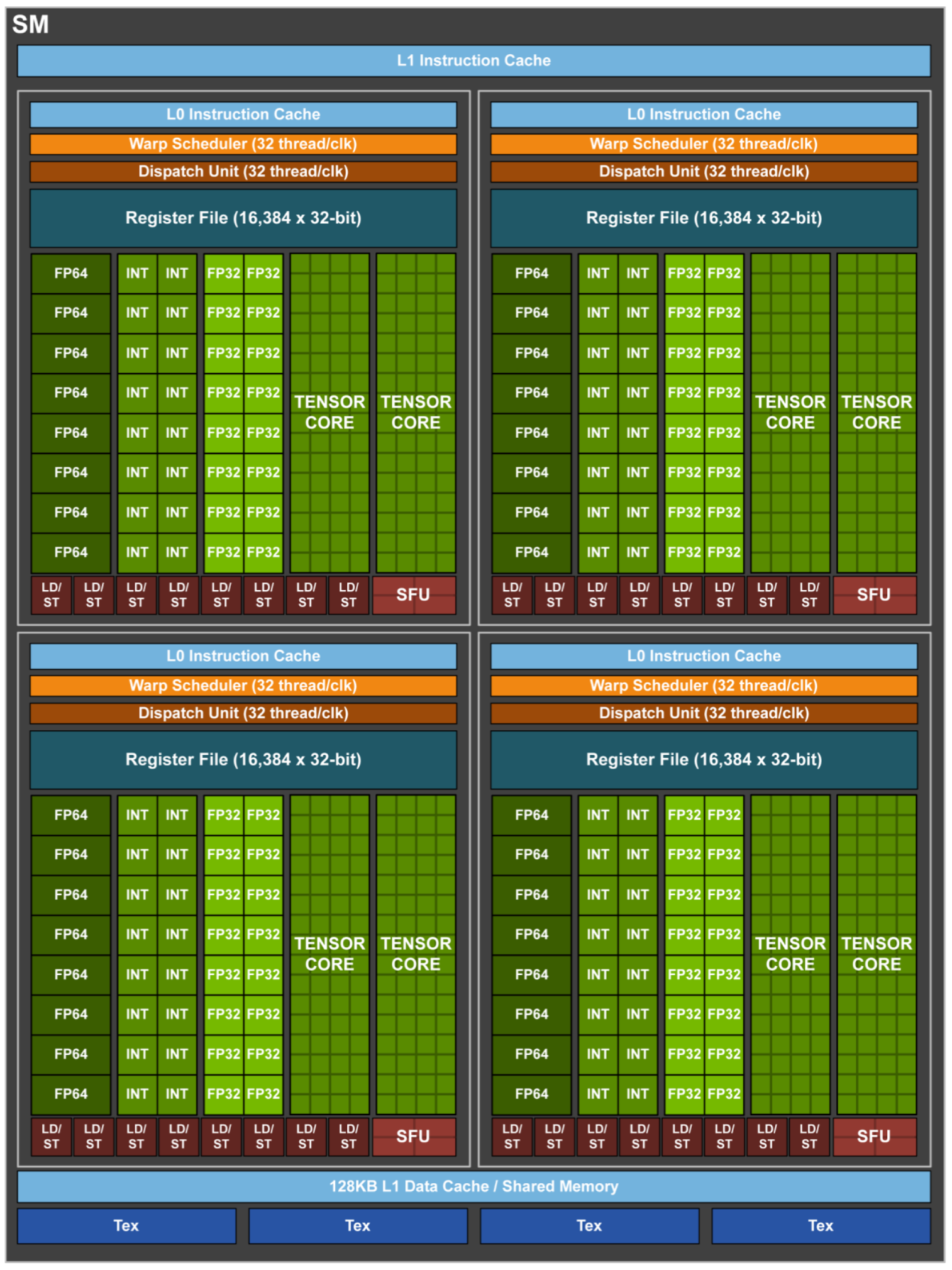
1 个 SM 中包含:
- 4 个 Warp scheduler
- 4 个 Dispatch Unit
- 64 个 FP32 Core
- 64 个 INT32 Core
- 32 个 FP64 Core
- 8 个 Tensor Core
- 32 个 LD/ST Unit
- 4 个 SFU
FP32 和 INT32 两组运算单元独立出现在流水线中,每个 Cycle 都可以同时执行 FP32 和 INT32 指令。
GPU 并行模式实现深度学习功能过于通用,最常见 Conv/GEMM 操作,依旧要被编码成 FMA,硬件层面还是需要把数据按:寄存器-ALU-寄存器-ALU-寄存器的方式来回搬运。
每个 Tensor Core 每个周期能执行 4 \(\times\) 4 \(\times\) 4 GEMM,即 64 个 FMA。虽然只支持 FP16 数据,但输出可以是 FP32,相当于 64 个 FP32 ALU 提供算力,能耗上有优势。
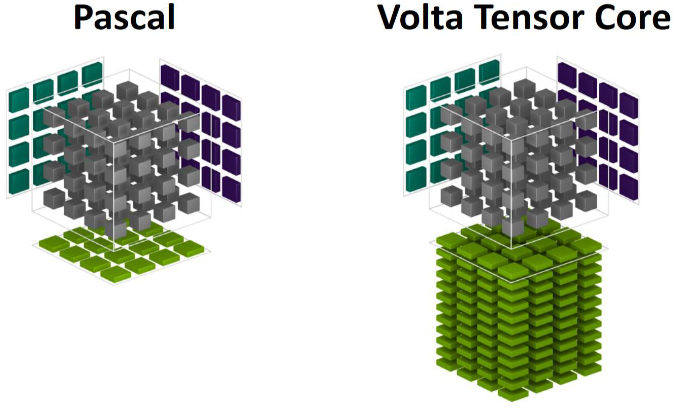
带有 Tensor Core 的基于 Volta 的 V100 GPU 计算的速度比基于 Pascal 的 Tesla P100 快 12 倍。
Turing
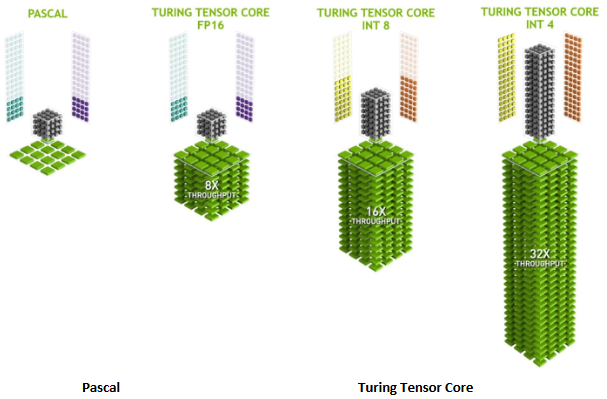
随着深度学习模型的量化部署渐渐成熟,Turing 架构中的 Tensor Core 增加了对 INT8/INT4/Binary 的支持,为加速深度学习的推理。RT Core(Ray Tracing Core)主要用来做三角形与光线的求交,并通过 BVH 结构加速三角形的遍历。由于布置在 block 之外,相对于普通 ALU 计算来说是异步的。里面分为两个部分,一部分检测碰撞盒来剔除面片,另一部分做真正的相交测试。图灵架构更多用于游戏领域。
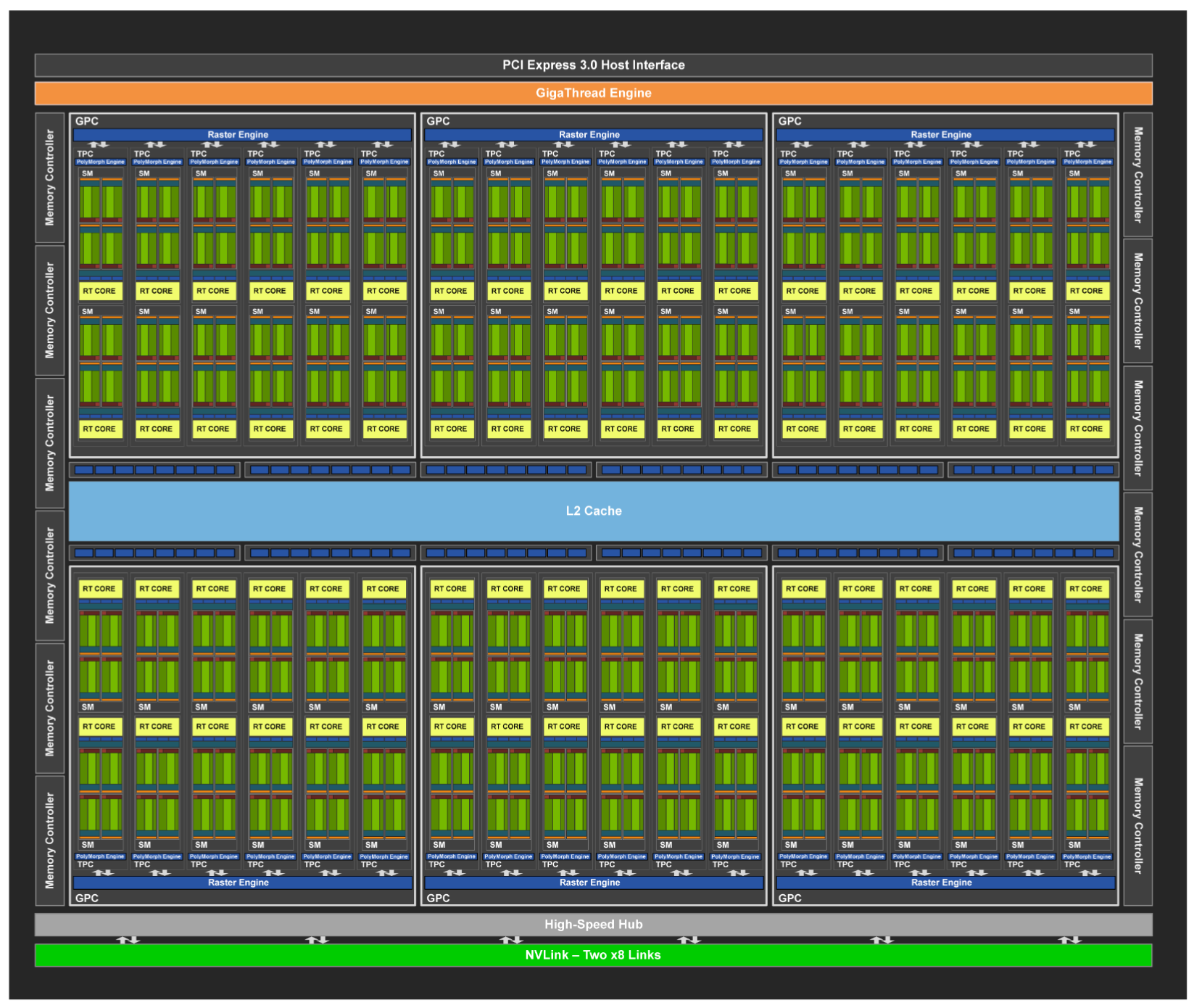
完整的 Turing 架构有 4608 个 CUDA Cores,72 个 RT Cores,576 个 Tensor Cores,288 个 Texture Units,12 个 32 为 GDDR6 内存控制器(总共 384 位)。TU102 GPU 还有 144 个 FP64 单元(每个 SM 有两个)。FP64 TFlops 速率是 FP32 操作 TFlops 的 \(\frac{1}{32}\),包含少量 FP64 硬件单元,以确保任何具有 FP64 代码的程序都能正确运行,
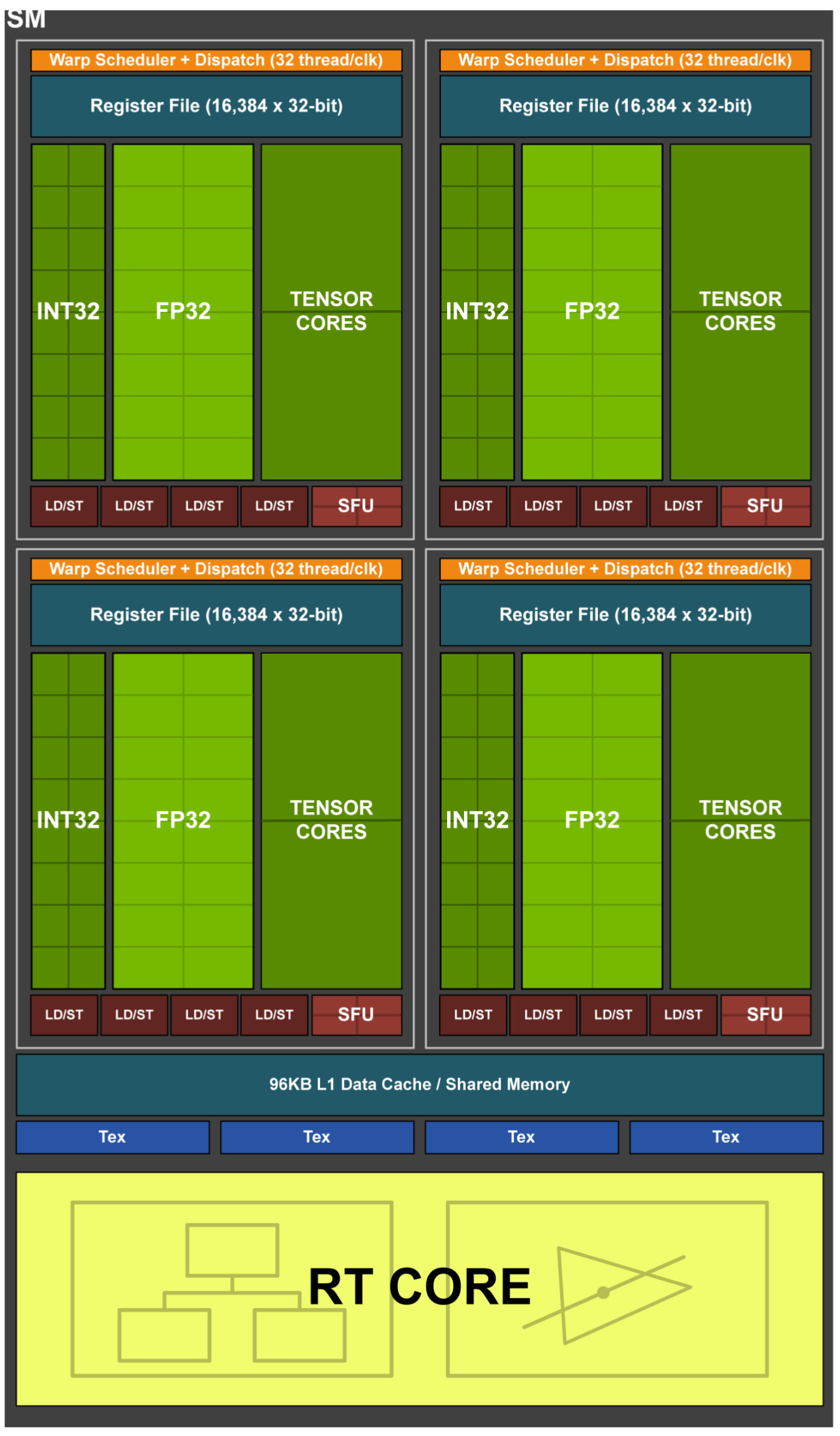
Turing 架构采用全新 SM 设计,融合了 Volta GV100 SM 架构中引入的许多功能。每个 TPC 包含两个 SM,每个 SM 总共有 64 个 FP32 内核和 64 个 INT32 内核。每个 SM 分为 4 个处理块,每个处理块有 16 个 FP32,16 个 INT32,2 个 Tensor Core,1 个 warp scheduler 和 1 个 dispatch scheduler。相比之下,Pascal GP10x GPU 每个 TPC 有 1 个 SM,每个 SM 有 128 个 FP32 核心。 Turing SM 支持 FP32 和 INT32 操作的并发执行,类似于 Volta GV100 GPU 的独立线程调度。每个 Turing SM 还包括 8 个混合精度 Turing Tensor Core和 1 个 RT Core。
Ampere
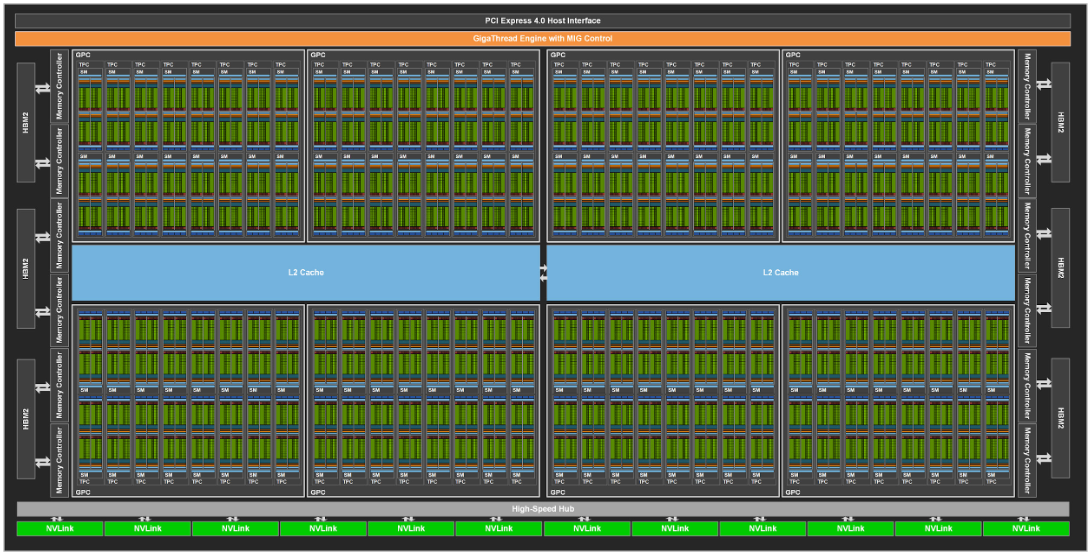
NVIDIA A100 基于 7nm Ampere GA100,具有 6912 个 CUDA Core 和 432 个 Tensor Core,54B 晶体管个数,108 个流式多处理器。采用第三代 NVLink,GPU 和服务器双向带宽为 4.8TB/s,GPU 之间的互连速度为 600GB/s。Tesla A100 在 5120 条内存总线上的 HBM2 内存可达 40GB。
- 超过 54B 个晶体管,成为此阶段世界上最大的 7nm 处理器;
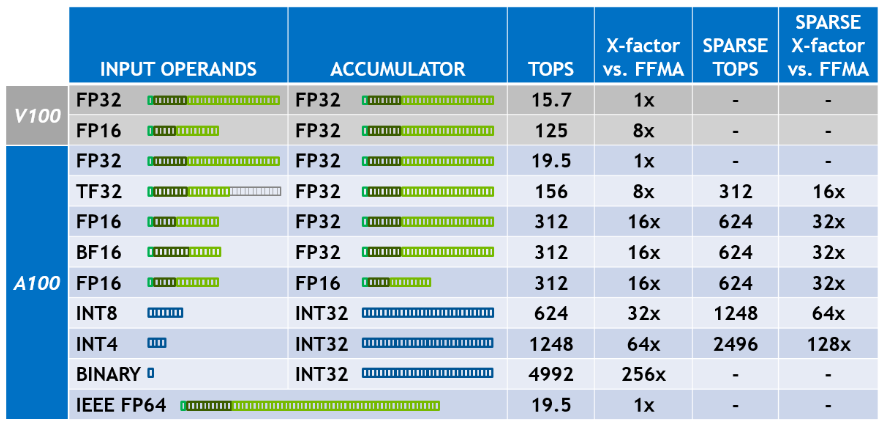
- Tensor Core3.0,新增了 TF32 包括针对 AI 的扩展,可使 FP32 精度的 AI 性能提高 20 倍;
- Multi-Instance GPU,多实例 GPU,将单个 A100 GPU 划分为多达 七个独立的 GPU,为不同任务提供不同的算力;
- NVLink 2.0,GPU 间高速连接速度加倍,可在服务器中提供有效的性能扩展;
- 结构稀疏性,利用了 AI 数学固有的稀疏特性来使性能提高一倍;
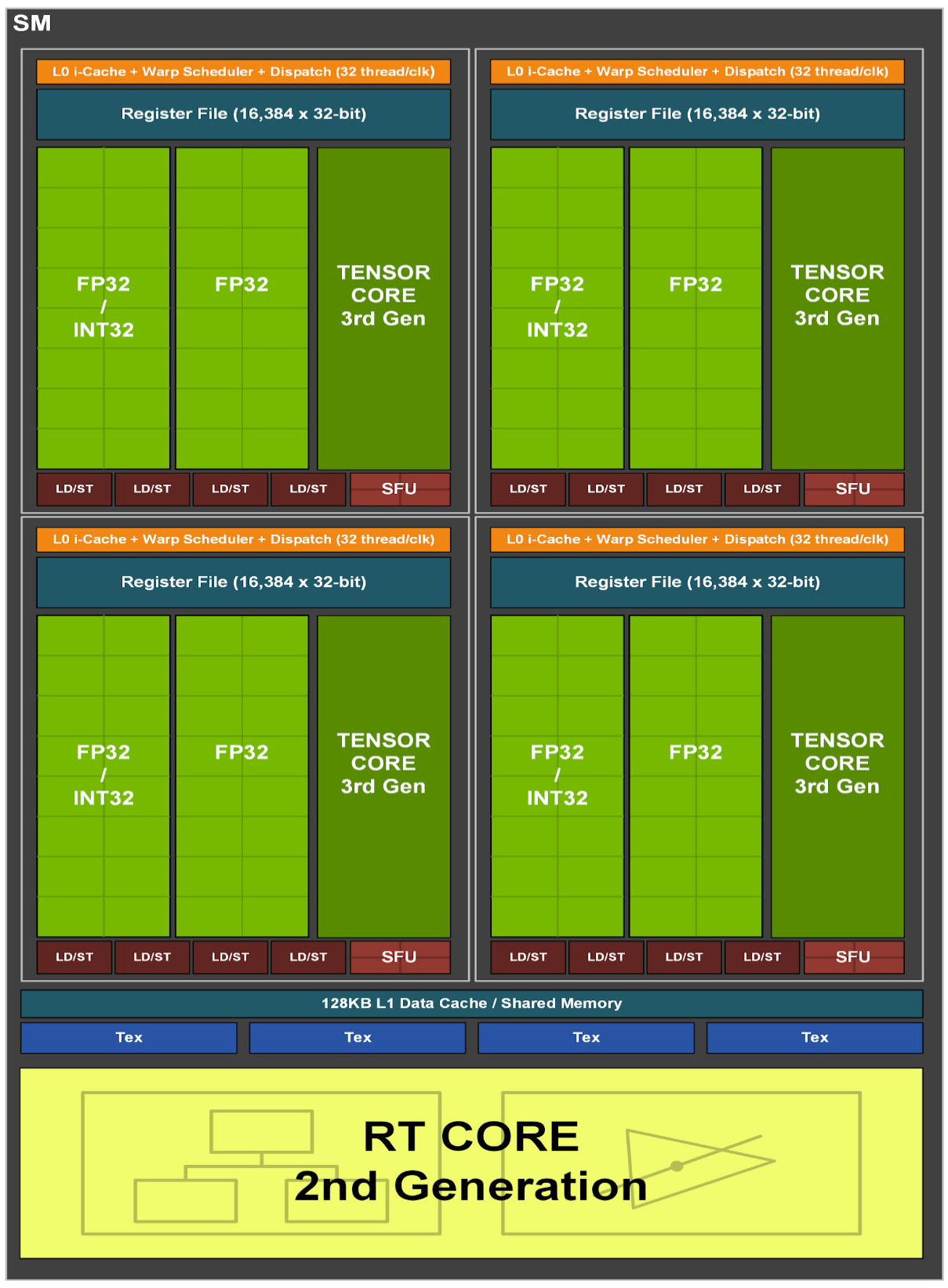
A100 SM 包括新的第三代 Tensor Core,每个内核每个时钟执行 256 次 FP16/FP32 FMA 操作。 每个 SM 有四个 Tensor Core,每个时钟总共提供 1024 个密集 FP16/FP32 FMA 操作,与 Volta 和 Turing 相比,每个 SM 的算力增加了 2 倍。新加入了 TF32(Tensor Float-32),BF16,FP64 的支持。BF16 是 IEEE FP16 的替代方案,包括 8 位指数、7 位尾数和 1 个符号位。 FP16 和 BF16 均已被证明可以在混合精度模式下成功训练神经网络,无需超参数调整即可匹配 FP32 训练结果。 Tensor Core 的 FP16 和 BF16 模式提供的吞吐量是 A100 GPU 中 FP32 的 16 倍。
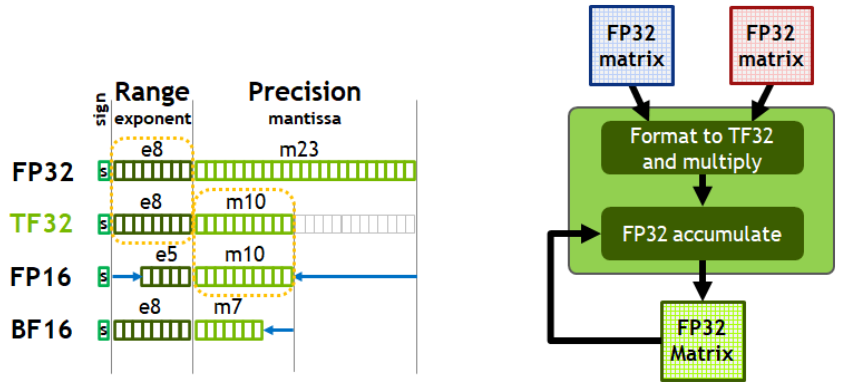
如今,AI 训练的默认使用 FP32,没有 tensor core 加速。 Ampere 架构引入了对 TF32 的新支持,使 AI 训练能够默认使用 tensor core,而无需用户进行任何操作。非张量操作继续使用 FP32 ,而 TF32 tensor core 读取 FP32 数据并使用与 FP32 相同的范围,但内部精度降低,生成 FP32 的输出。 TF32 包括 8 位指数(与 FP32 相同)、10 位尾数(与 FP16 精度相同)和 1 个符号位。

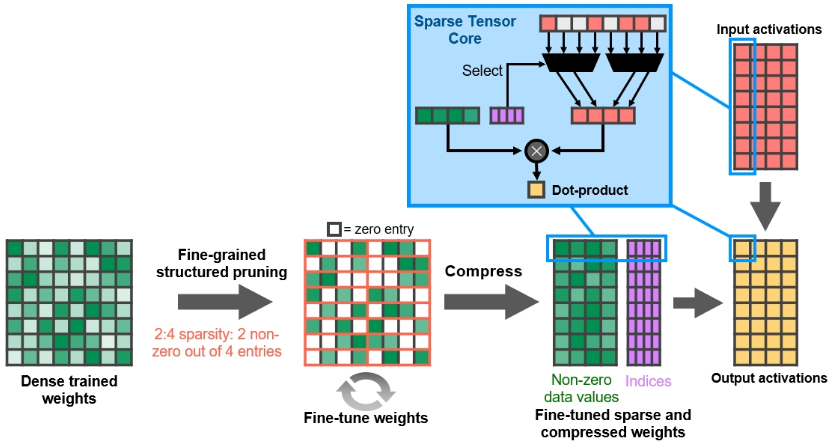
细粒度的结构化稀疏矩阵,Tensor Core 支持一个 2:4 的结构化稀疏矩阵与另一个稠密矩阵直接相乘。先使用密集权重对神经网络进行训练,然后应用细粒度的结构化剪枝,最后通过额外的训练步骤对剩余的非零权重进行微调。A100 的新 Sparse MMA 指令会跳过对零值的计算,从而使 Tensor Core 计算吞吐量翻倍。
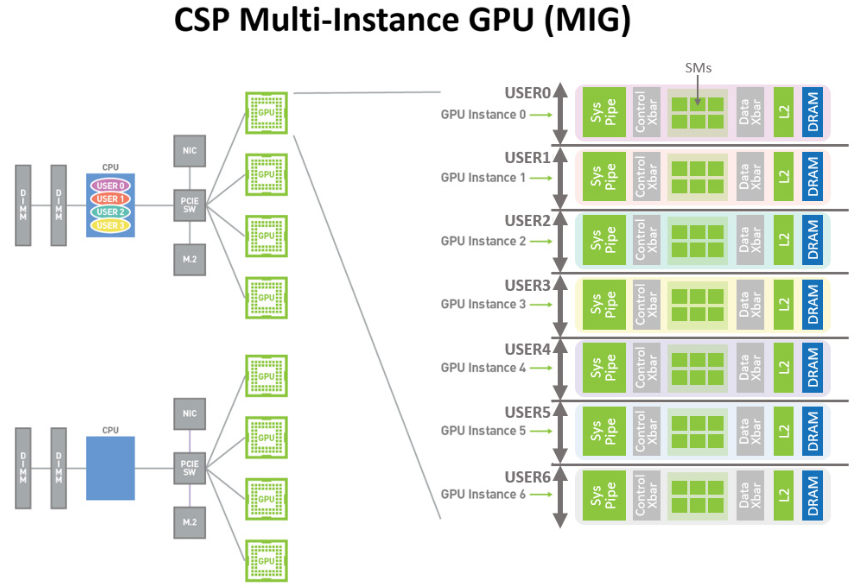
每个 A100 可以被分为 7 个 GPU 实例被不同的任务使用,用户可以将这些虚拟的 GPU 实例当成真实的 GPU 使用。创建 GPU 实例可以被视为将一个大 GPU 拆分为多个较小的 GPU,每个 GPU 实例都具有专用的计算和内存资源。每个 GPU 实例的行为就像一个更小的、功能齐全的独立 GPU,其中包括预定义数量的 GPC、SM、L2 缓存切片、内存控制器和帧缓冲内存。
Ada Lovelace
GeForce RTX 4090 是首款基于全新 Ada 架构的 GeForce 显卡。 GeForce RTX 4090 的核心是 AD102 GPU,它是基于 NVIDIA Ada 架构的最强大的 GPU。 AD102 旨在为游戏玩家和创作者提供革命性的性能,并使 RTX 4090 在许多游戏中能够以 4K 分辨率持续提供每秒超过 100 帧的帧速率。
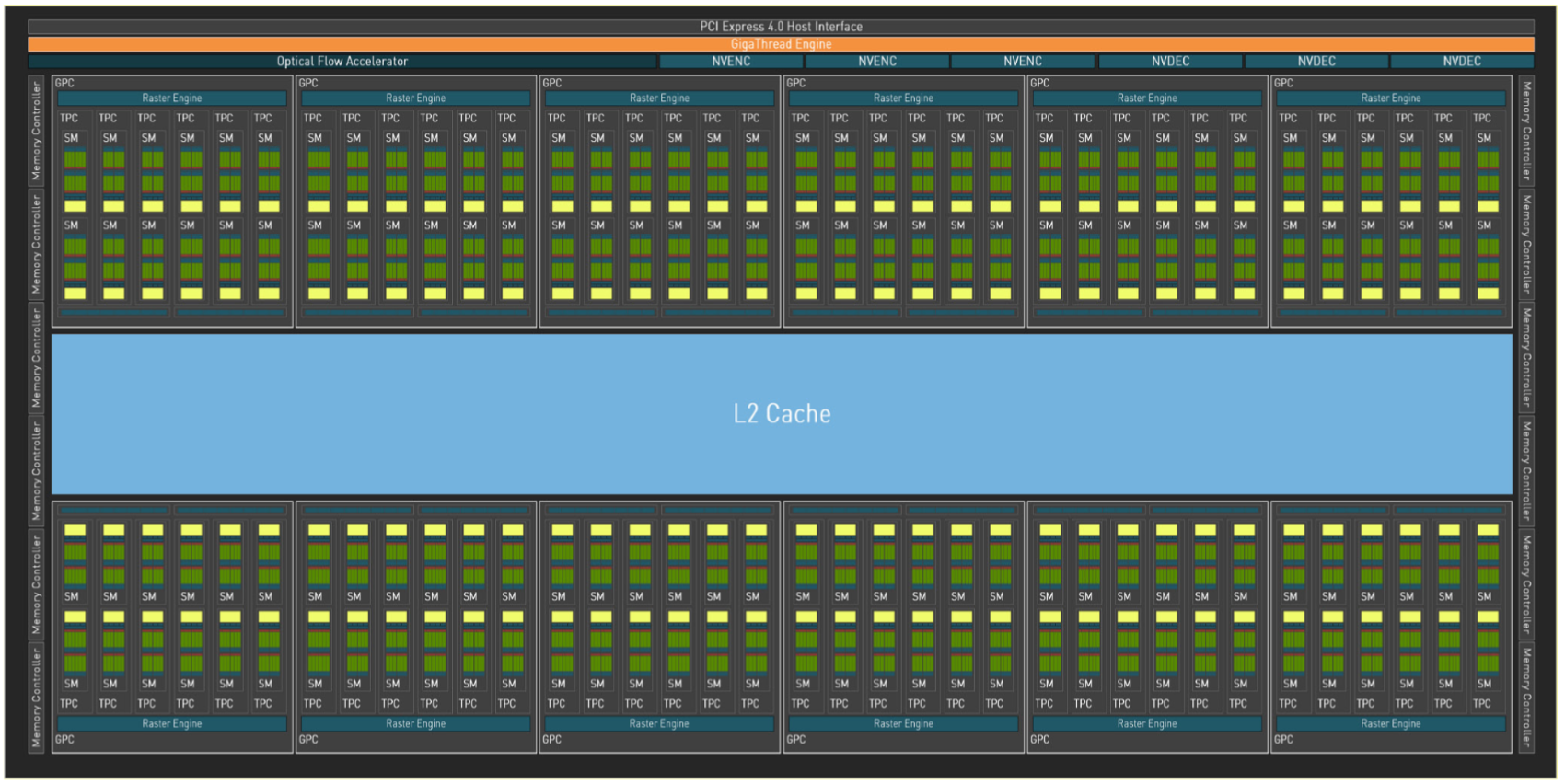
完整的 AD102 GPU 包括:
- 12 个图形处理集群 (GPC)
- 72 个纹理处理集群 (TPC)
- 144 个流多处理器 (SM)
- 一个带有 12 个 32 位内存控制器的 384 位内存接口
- 18432 个 CUDA Core
- 144 个 RT Core
- 576 个 Tensor Core
- 576 个 Texture Units
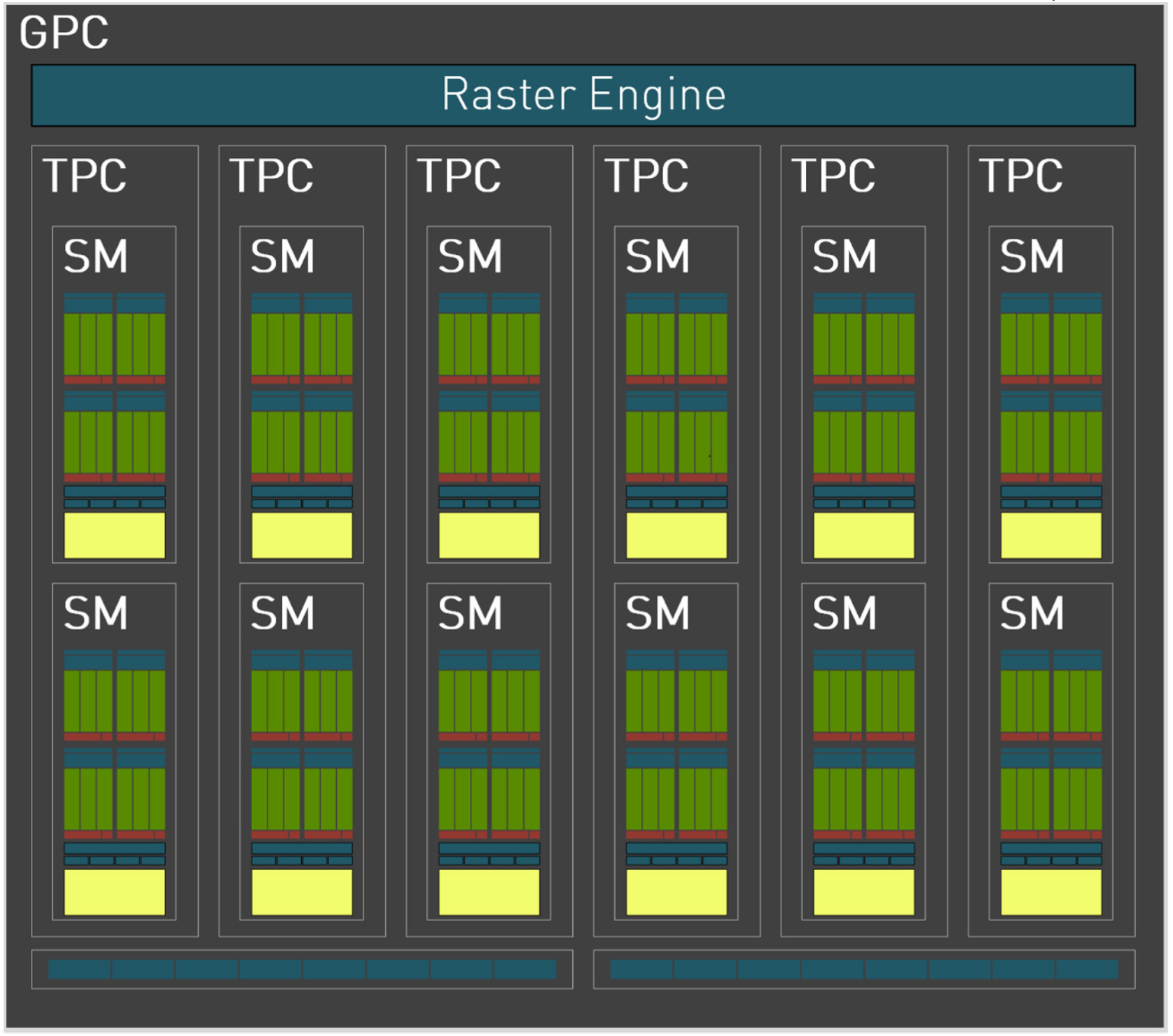
GPC 是所有 AD10x Ada 系列 GPU 中占主导地位的高级硬件块,所有关键图形处理单元都位于 GPC 内。每个 GPC 包括一个专用光栅引擎、两个光栅操作 (ROP) 分区(每个分区包含八个单独的 ROP 单元)和六个 TPC。每个 TPC 包括一个 PolyMorph 引擎和两个 SM。
AD10x GPU 中的每个 SM 包含 128 个 CUDA 核心、1 个 Ada 第三代 RT 核心、4 个 Ada 第四代 Tensor Core、4 个 Texture units、1 个 256 KB 寄存器文件和 128 KB L1/Shared Memory,可配置为根据图形或计算工作负载的需求不同的内存大小。
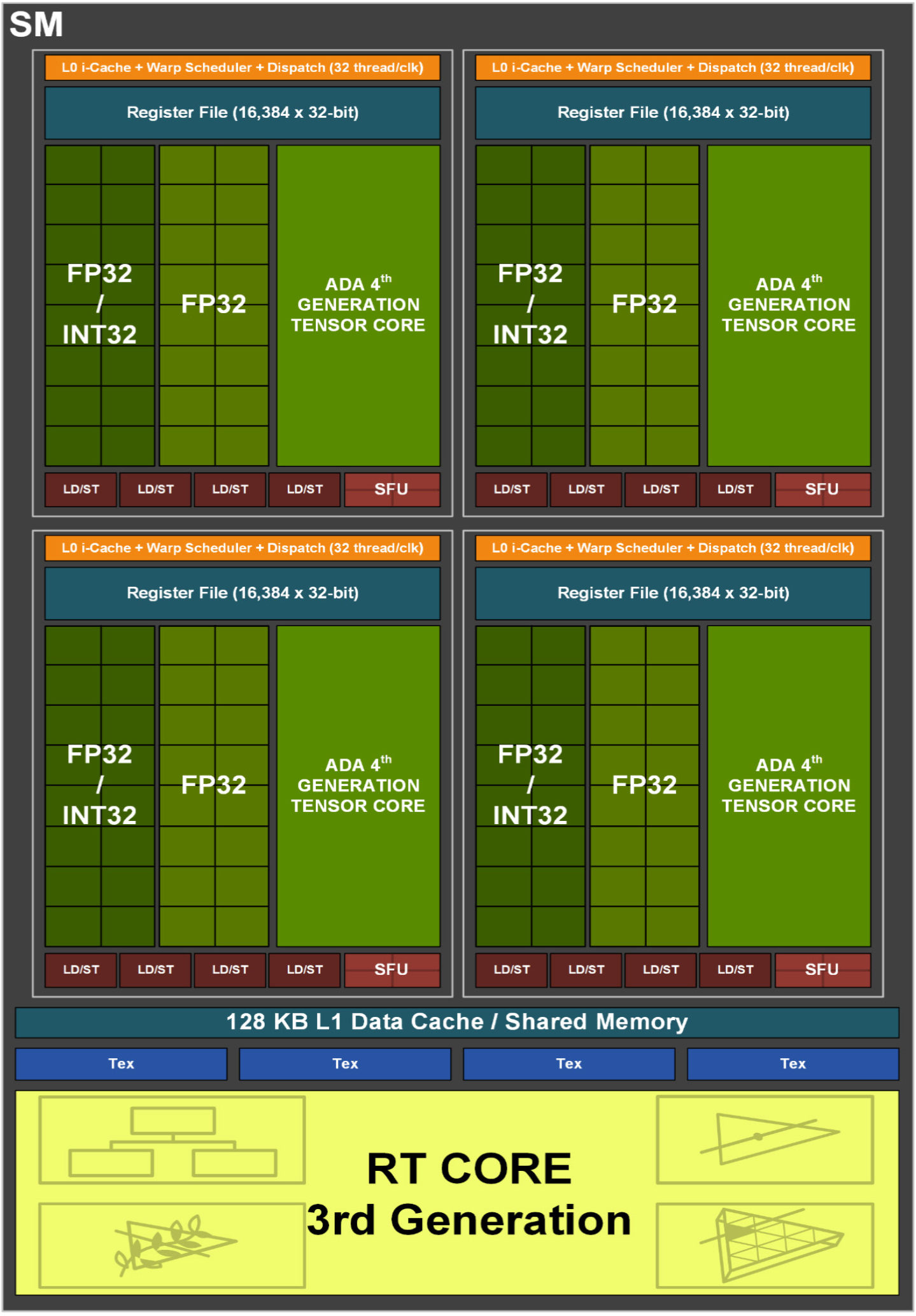
与之前的 GPU 一样,AD10x SM 分为 4 个处理块(或分区),每个分区包含 64 KB 寄存器文件、L0 指令缓存、1 个 warp 调度程序、1 个调度单元、16 个专用于处理 FP32 的 CUDA 核心操作(每个时钟最多 16 个 FP32 操作)、16 个可处理 FP32 或 INT32 操作的 CUDA 核心(每个时钟 16 个 FP32 操作或每个时钟 16 个 INT32 操作)、一个 Ada 第四代 Tensor Core、四个 LD/ST 单元,以及执行先验和图形插值指令的特殊功能单元(SFU)。
Hopper
NVDIA Grace Hopper Superchip 架构将 NVIDIA Hopper GPU 的突破性能与 NVIDIA Grace CPU 的多功能性结合在一起,在单个超级芯片中与高带宽和内存一致的 NVIDIA NVLink Chip-2-Chip(C2C)互连相连,并且支持新的 NVIDIA NVLink 切换系统。
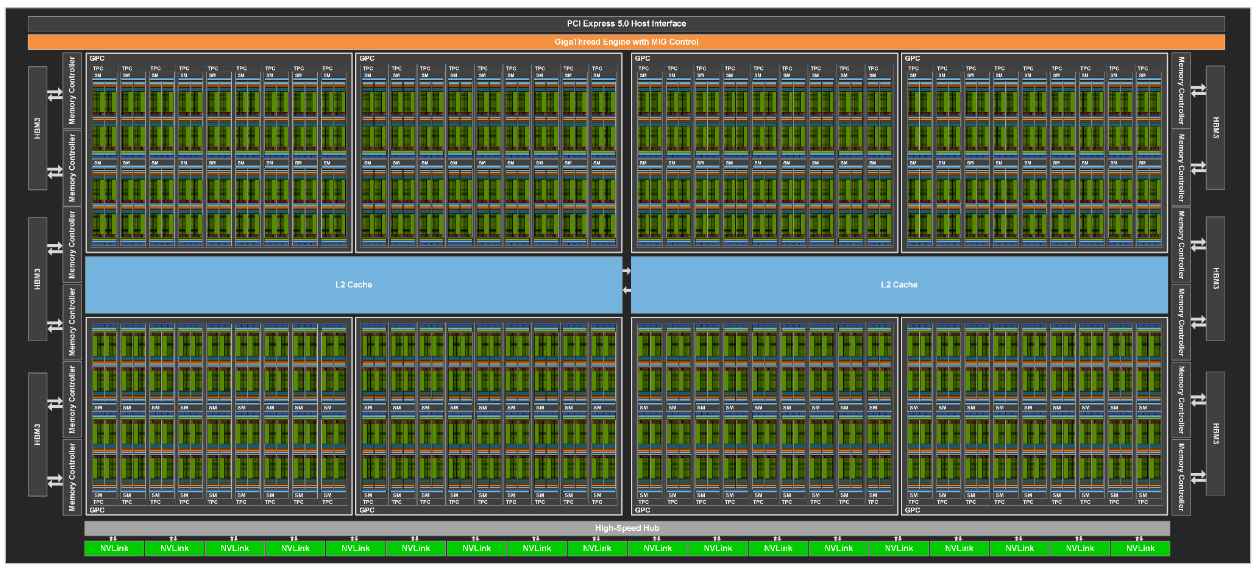
GPC 8组,66 组 TPC,132 组 SM,总共有 16896 个 CUDA Core,528 个 Tensor Core,50MB 二级缓存。显存为新一代 HBM3,容量为 80GB,位宽 5120-bit,带宽高达 3TB/s。
Hopper 架构是第一个真正的异构加速平台,有以下改进:
- NVIDIA Grace CPU:
- 72 个 Arm Neoverse V2 内核,每个内核 Armv9.0-A ISA 和 4 个 128 为 SIMD 单元;
- 512 GB LPDDR5X 内存,提供高达 546 GB/s 的内存带宽;
- 117 MB 的 L3 缓存,内存带宽高达 3.2 TB/s;
- 64 个 PCI-E Gen5 通道;
- NVIDIA Hopper GPU:
- 144 个 Gen4 Tensor Core,Transformer Engine,DPX 和 3 倍高 FP32 和 FP64 的 SM;
- 96 GB HBM3 内存提供高达 3000 GB/s 的速度;
- 60 MB 二级缓存;
- NVLink 4 和 PCI-E 5;
- NVIDA NVLink-C2C:
- Grace CPU 和 Hopper GPU 之间的硬件一致性互连;
- 高达 900 GB/s 的总带宽,450 GB/s/dir;
- 扩展 GPU 内存功能使 Hopper GPU 能够将所有 CPU 内存寻址为 GPU 内存。每个 Hopper GPU 可以在超级芯片内寻址多达 608 GB 内存;
- NVIDIA NVLink 切换系统:
- 使用 NVLink 4 连接多达 256 个 NVIDIA Grace Hopper 超级芯片;
- 每个连接 NVLink 的 Hopper GPU 都可以寻址网络中所有超级芯片的所有 HBM3 和 LPDDR5X 内存,最高可达 150 TB 的 GPU 可寻址内存;
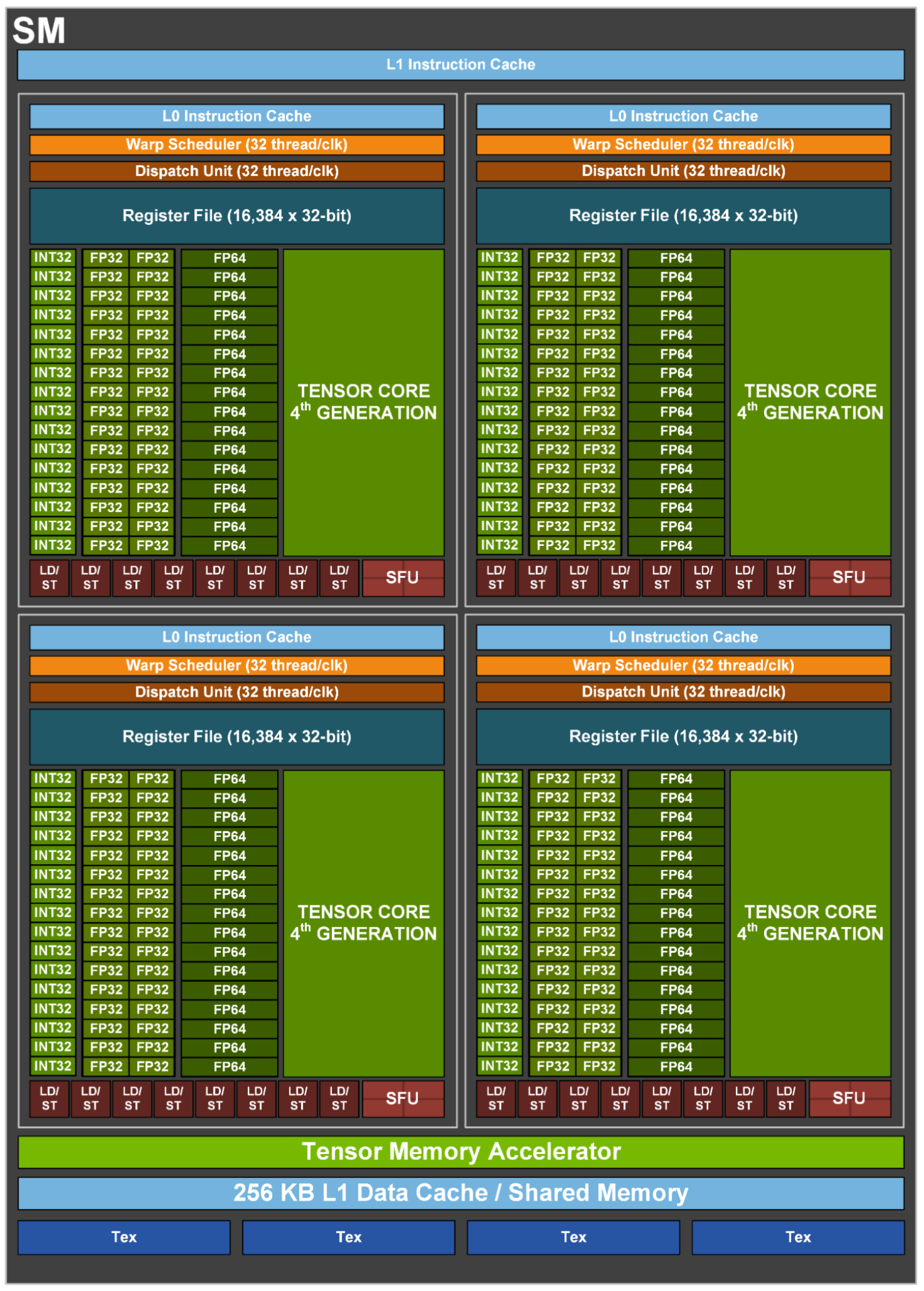
每个 SM:
- 4 个 Warp Scheduler,4 个 Dispatch Unit(与 A100 一致);
- 128 个 FP32 Core(4 * 32)(相比 A100 翻倍);
- 64 个 INT32 Core(4 * 16)(与 A100 一致);
- 64 个 FP64 Core(4 * 16)(相比 A100 翻倍);
- 4 个 Tensor Core(4 * 1);
- 32 个 LD/ST Unit(4 * 8)(与 A100 一致);
- 16 个 SFU(4 * 4)(与 A100 一致);
- 相比 A100 增加了一个 Tensor Memory Accelerator;
每个 Process Block:
- 1 个 Warp Scheduler,1 个 Dispatch unit;
- 32 个 FP32 Core;
- 16 个 FP64 Core;
- 1 个 Tensor Core;
- 8 个 LD/ST Unit;
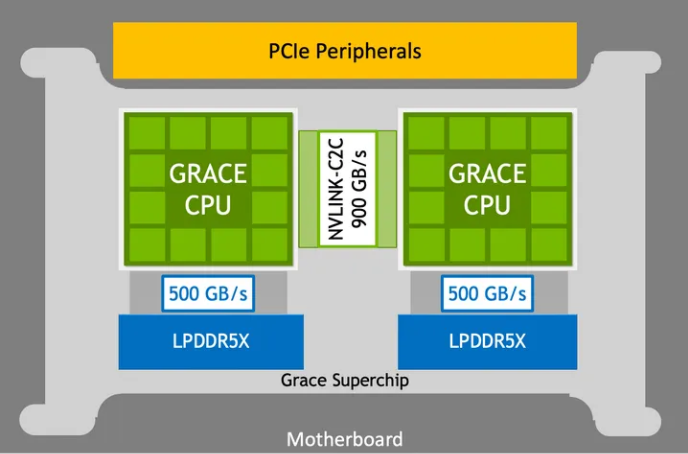
- 4 个 SFU;
NVIDIA Grace Hopper Superchip 将节能、高带宽的 NVIDIA Grace CPU 与功能强大的 NVIDIA H100 Hopper GPU 结合使用 NVLink-C2C,并且支持新的 NVIDIA NVLink 切换系统,以最大限度地提高强大的高性能计算 (HPC) 和巨型 AI 工作负载的能力。NVIDIA Grace CPU Superchip 结合了两个连接超过 900 GB/s 双向带宽 NVLink-C2C 的 NVIDIA Grace CPU,提供 144 个高性能 Arm Neoverse V2 内核和高达 1 TB/s 带宽的数据中心级 LPDDR5X 内存,带纠错码(ECC)内存。