随着深度神经网络模型的加深,模型的准确性也得到了相应的提升,但由于硬件条件的限制,在单个设备上训练数十亿至数万亿参数十分困难。当前,通常会使用数据并行和模型并行的方法来解决训练大型模型显存受限的问题,但数据并行和模型并行均存在不足之处。数据并行虽然不需要进行频繁的通信,但是需要在每个处理器上复制一份完整的模型状态,造成模型的冗余;而模型并行虽然对模型状态进行了划分,能够减少模型状态冗余,更高效地使用内存,但是会导致计算粒度过细,需要频繁进行通信。
微软提出了 ZeRO,零冗余优化器来消除了模型并行和数据并行训练中的内存冗余,同时也保持了低通信量和高计算粒度。
本文认为,模型训练的过程中,内存消耗主要分为两个部分:
- 模型状态,包括优化器状态(optimizer state)、梯度和参数,其中,优化器状态包括动量(momentum)和方差(variance);
- 剩余状态,包括中间激活值(activations)、临时缓冲区和不可用的显存碎片。
本文分别针对以上两个消耗内存的主要部分提出了两种不同的方法,ZeRO-DP 和 ZeRO-R。
优化模型状态(model states)
ZeRO-DP 将模型状态进行切分,使每个处理器只保留模型状态的一部分,减少模型的冗余存储。提出了三个优化的阶段:
-
优化器状态(optimizer states)
在每个 GPU 中保存全部的参数和梯度,但是只保存 \(\frac{1}{N_d}\) 的优化器状态变量。实验表明,切分优化器状态使内存占用减少 4 倍,与 DP 具有相同的通信量;
-
梯度 + 优化器状态(gradients + optimizer states)
每个 GPU 中只保存 \(\frac{1}{N_d}\) 的梯度,实验表明,切分梯度和优化器状态使内存占用减少 8 倍,与 DP 具有相同的通信量;
-
参数 + 梯度 + 优化器状态(parameters + gradients + optimizer states)
每个 GPU 中只保存 \(\frac{1}{N_d}\) 的参数 ,实验表明,切分参数、梯度和优化器状态能使内存占用减少 64 倍(内存减少量与 DP 划分的份数呈线性关系),通信量仅增加 50%。
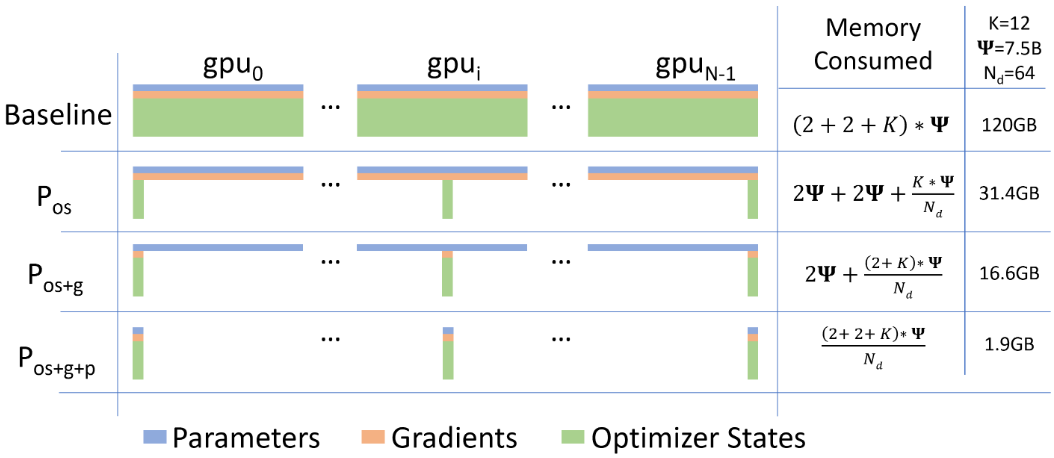
\(\Psi\): 模型大小(参数的数量),图中模型大小为 7.5B
K: 存储优化器状态要消耗的内存倍数,对于混合精度的 Adam 优化器而言,K = 12
\(N_d\): 数据并行度,数据并行度为 \(N_d = 64\),即在 64 块 GPU 上进行训练
优化剩余状态(residual states)
ZeRO-R 针对中间激活值(activations)、临时缓冲区(buffer)和不可用的显存碎片占用,提出了以下优化点:
- 使用针对激活值的检查点(checkpoint)来节省内存,同时还对激活值进行切片,根据需要将激活值数据卸载到 CPU 来减少激活值(activations)的显存占用;
- 定义了适当的临时缓冲区大小,使内存和计算效率平衡;
- 根据不同张量(tensor)的生命周期,主动管理内存,减少内存碎片产生的概率;
ZeRO-DP 和 ZeRO-R 结合起来被称为 ZeRO,零冗余优化器,既解决了数据并行(DP)中内存效率低下的问题,又解决了模型并行中计算和通信效率低下的问题。
ZeRO 和模型并行相结合
在激活内存占用非常大的时候,可以结合模型并行减少激活内存的占用。在模型较小的时候,单独使用数据并行会导致 batch size 过大可能无法收敛,使用模型并行可以在加速训练的同时减小 batch size 到合适的值,帮助模型收敛。在将 ZeRO 和模型并行结合时,理论上最多可以减少 \(N_d \times N_m\) 倍的内存占用。
实验中,ZeRO 训练的吞吐量和加速比与 SOTA 对比结果如下:
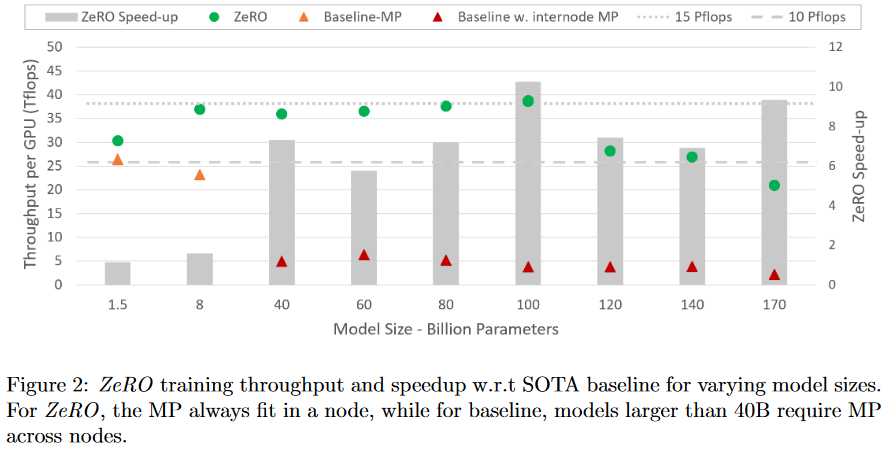
- Model Size:与模型并行相结合,ZeRO-100B 可以有效运行 170B 参数量的模型,而单独使用 Megatron 等现有系统无法扩展超过 40B 参数,如上图所示,与 SOTA 相比,模型大小增加了 8x 以上。
- Speed:提高内存的效率可以提高吞吐量和加快训练速度。如上图 Fig2,ZeRO 在 400 个 Nvidia V100 GPU 集群上运行 100B 参数模型,每个 GPU 超过了 38 TFlops,总性能超过 15 Petaflops。与相同模型大小的 SOTA 相比,训练速度提高了 10x 以上。
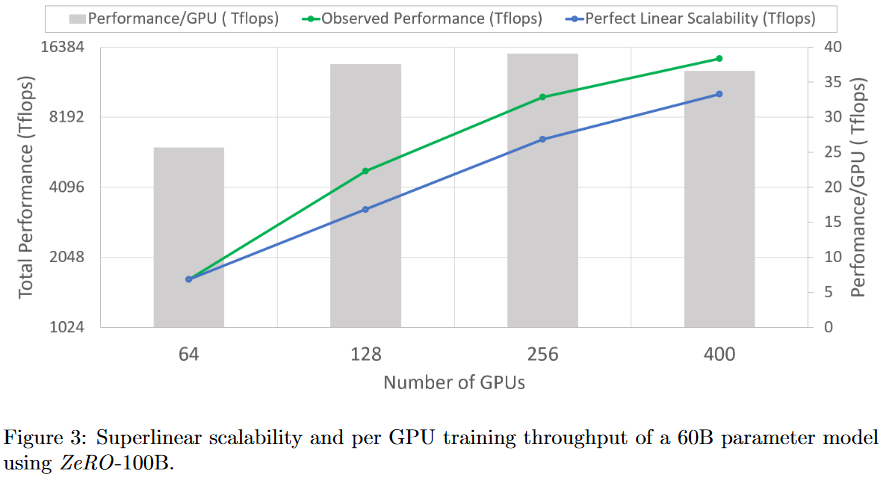
- Scalability:当使用64-400个GPU时,性能呈现超线性加速,当 GPU 数量增加一倍时,性能会增加一倍以上。当增加 DP 程度时,它会减少模型状态的内存占用,使得每个 GPU 能够承载更大的 batch size,从而获得更好的性能。预计当 GPU 的数量增加到 400 以上时,这种行为会进一步持续。
- Democratization of Large Model Training:ZeRO-100B 使得 130亿参数的模型只需重构即可训练。相比之下,现有系统(如PyTorch Distributed Data Parallel)在 14 亿参数的规模上就会出现内存不足的情况。
- New SOTA Model:ZeRO 支持拥有 170 亿参数的 Turing-NLG 模型,并成为了 SOTA。
显存都去哪了?
正如上述提到的,在模型训练期间,大部分的显存被模型状态(model states)消耗,其中包含优化器状态、梯度、参数组成的张量。除了这些模型状态之外,其余的显存都被激活值、临时缓冲区(buffer)和显存碎片消耗,并将这部分称为冗余状态(residual states)。
模型状态:优化器状态、梯度和参数
以 Adam 为例,它需要存储两个优化器状态:时间平均动量和梯度方差来计算更新。Adam 在训练时使用指数移动平均来计算梯度,需要保存梯度的拷贝,以稳定更新参数。Adam 还使用了自适应学习率机制,会为每个参数自动调整学习率,学习率的自适应依赖于每个参数的梯度方差。为了计算梯度方差(variance),就需要保存梯度的 momentum,以便在参数更新时更好地适应局部梯度的特性。因此,要使用 Adam 训练模型,必须有足够的内存来保存梯度动量和方差的副本。此外,需要有足够的内存来存储梯度和权重本身。在这三种类型的参数相关张量中,优化器状态通常是消耗最多的内存,特别是在应用混合精度训练时。
在使用混合精度训练时,将参数和激活值存储为 fp16, 并在正向和反向传播训练期间都使用 fp16 进行计算,在反向传播结束之后保存参数和优化器状态的 fp32 副本来保证计算的精确性。使用 Adam 对具有 \(\Psi\) 个参数的模型进行混合精度训练需要足够的内存来存储参数和梯度的 fp16 副本,内存需求分别为 \(2\Psi\) 和 \(2\Psi\) 字节。此外,还需要存储优化器状态:参数、动量和方差的 fp32 副本,内存需求分别为 \(4\Psi\)、\(4\Psi\) 和 \(4\Psi\) 字节。混合精度 Adam 总共需要 \(2\Psi + 2\Psi + 12\Psi = 16\Psi\) 字节的内存需求。对于像 GPT-2 这样的 1.5B 参数的模型,至少需要 24GB 的内存,远高于 3GB 内存来存储 fp16 参数的需求。
冗余内存消耗
训练期间,激活值(activations)会占用大量内存。举个例子,序列长度 sequence length 为 1K,批量大小 batch size 为 32 训练的 1.5B 参数量的 GPT-2 模型需要大约 60GB 的内存。
激活值占用内存 = Transformer 层数 \(\times\) hidden_dim \(\times\) batch_size \(\times\) seq_len
- Activations:使用激活值检查点(checkpoint)的技术可以将内存消耗减少大约总激活值的 \(\frac12\) 次方,如将上述模型的激活值内存占用减少到约 8GB,但代价是会增加 33% 的重计算开销。但是对于较大的模型,即使使用了激活检查点,激活内存也会变得相当大。例如,即使使用激活检查点,训练 batch size 为 32,且具有 1000 亿个参数的 GPT-like 的模型需要大约 60GB 的内存。
- Temporary buffers:对于大型模型来说,用于存储中间结果的临时缓冲区会消耗大量内存。梯度 all-reduce,或者梯度正则计算时会将所有梯度融合到一个 flattened buffer 中,尽管梯度可以以 fp16 存储,但 buffer 可能还是 fp32.对于一个具有 1.5B 参数的模型,一个 flattened fp32 buffer 要占用 6GB 的内存。
- Memory Fragmentation:如果没有足够的连续内存来满足内存请求,即使总共可用的内存大于请求的内存,内存请求也会失败。在训练非常大的模型时观察到明显的内存碎片,导致内存不足,在某些极端的情况下会有超过 30% 的内存碎片存在。